一致性协议:Raft
由于Paxos算法相对来说较为复杂且难以理解,因此在后来又出现了一种用于替代Paxos的算法——Raft
Raft 算法是一种简单易懂的共识算法,所谓共识,就是多个节点对某个事情达成一致的看法,即使是在部分节点故障、网络延时、网络分割的情况下。它依靠状态机和主从同步的方式,在各个节点之间实现数据的一致性。
Raft算法的核心主要为以下两部分,下面将进行具体讲解
- 主节点选举(Leader Election)
- 数据同步(Log Replication)
状态机
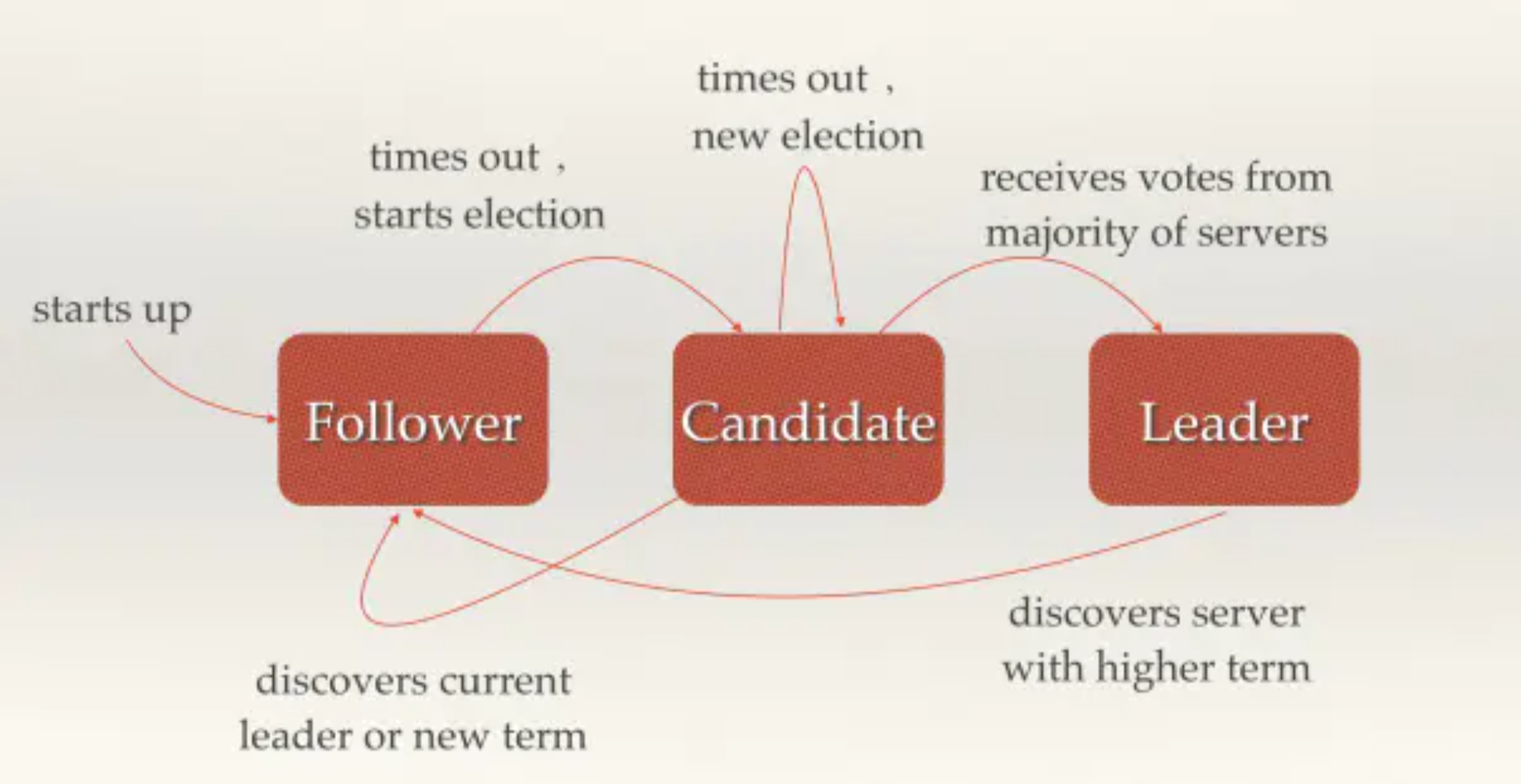
在Raft中节点中存在三种状态,状态之间可以相互进行转换
-
Leader(主节点)
-
Follower(从节点)
-
Candidate(竞选节点)
同时,每个节点上会存放一个倒计时器(Election Timeout),时间随机在150ms到300ms之间。Leader节点会周期性的向所有Follower发送一个心跳包(Heartbeat),收到心跳包的节点会将其计时器清零后重新计时,如果在倒计时结束前没有收到Leader的心跳包,此时Follower就会变为Candidate,开始进入竞选状态。
具体的状态转移如下图
执行流程
主节点选举
介绍了状态机后,下面就来看看主节点的选举流程
第一步,在一开始时,由于没有Leader,所以此时所有节点的身份都是Follower,每一个节点上都有着自己的计数器,当计时器达到了超时时间后,该节点就会转换为Candidate,开始选举过程。
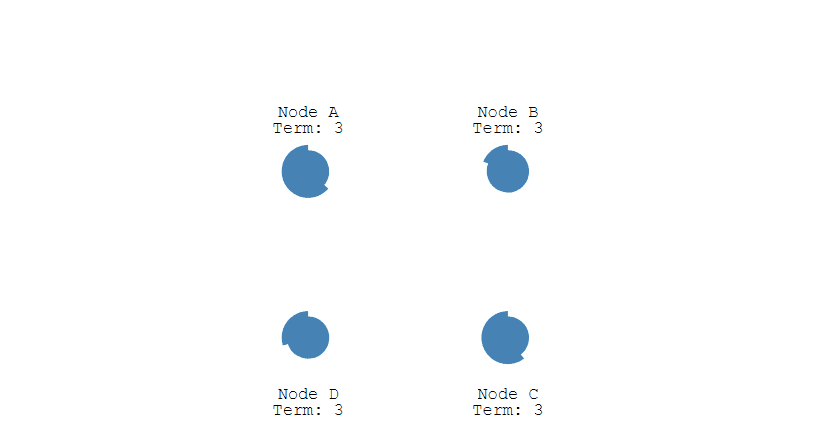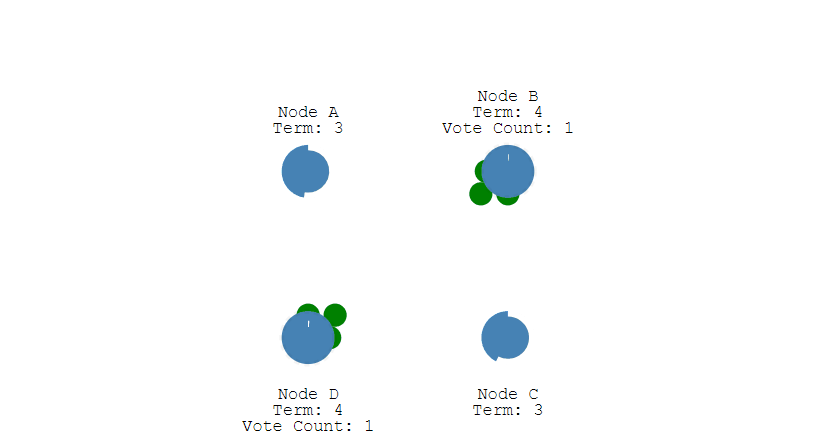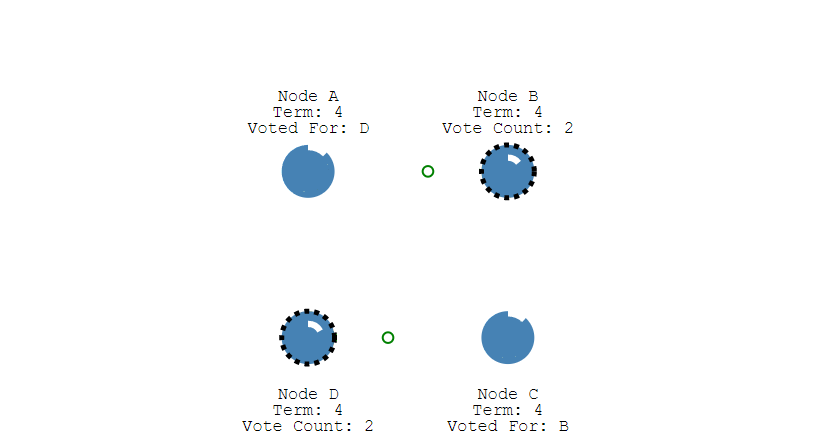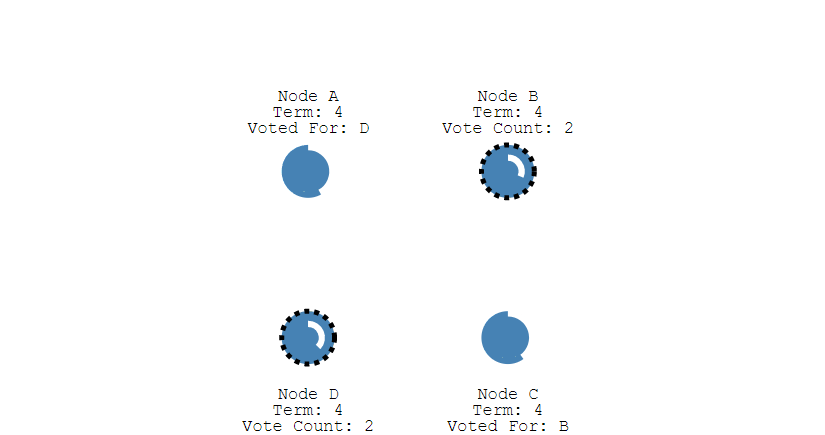
第二步,成为Candidate的节点首先会给自己投一张票,然后向集群中的其他所有节点发起投票请求。
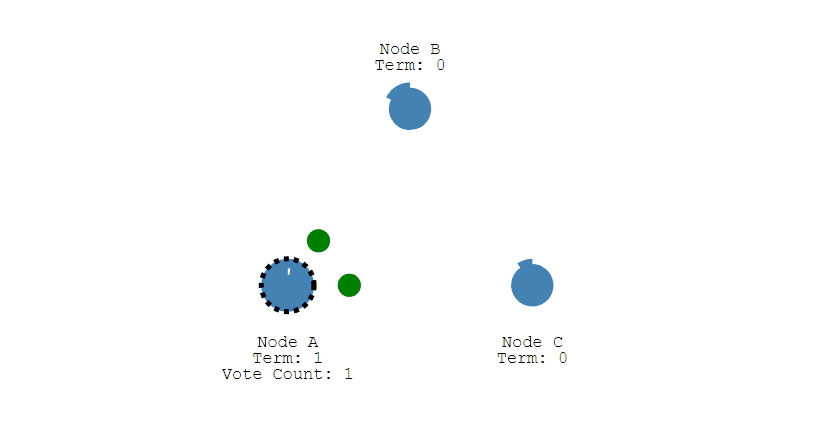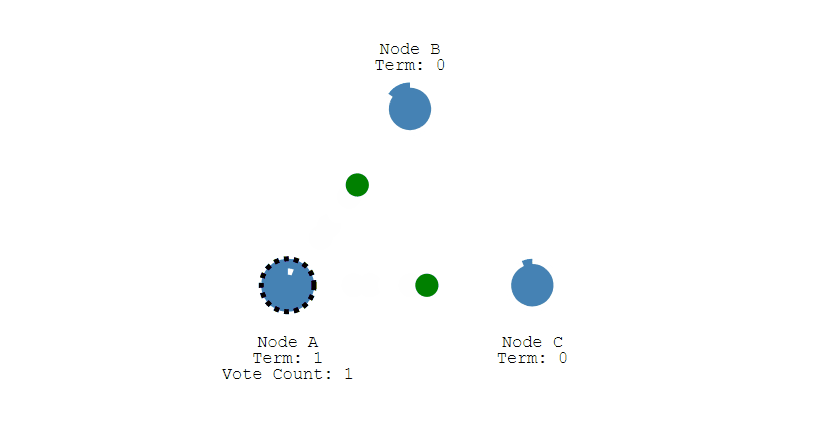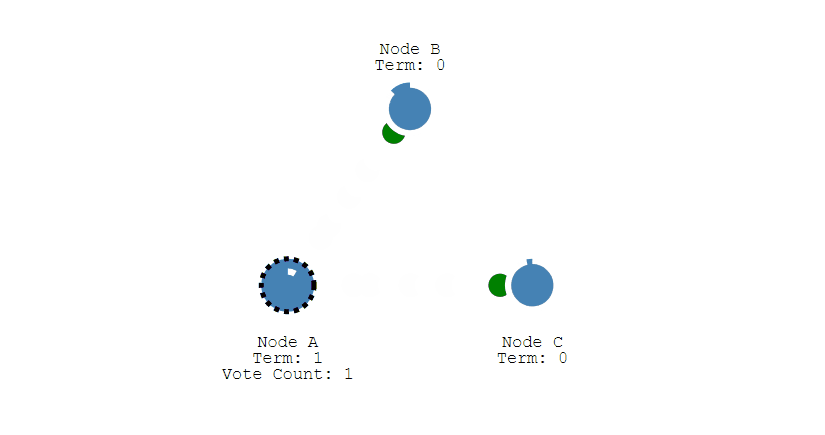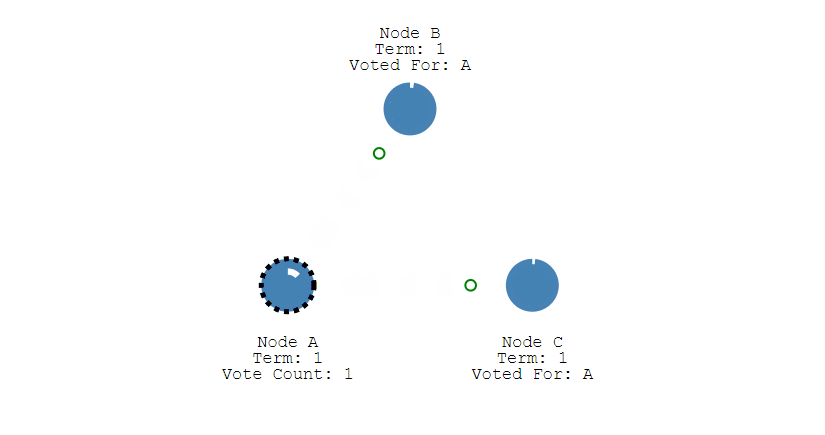
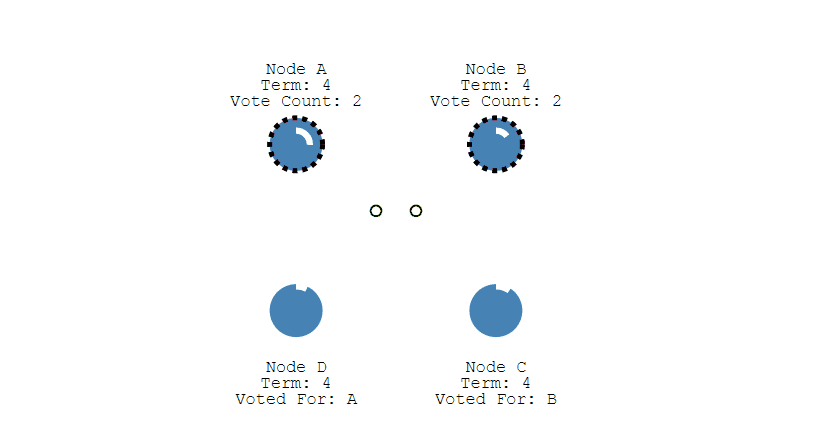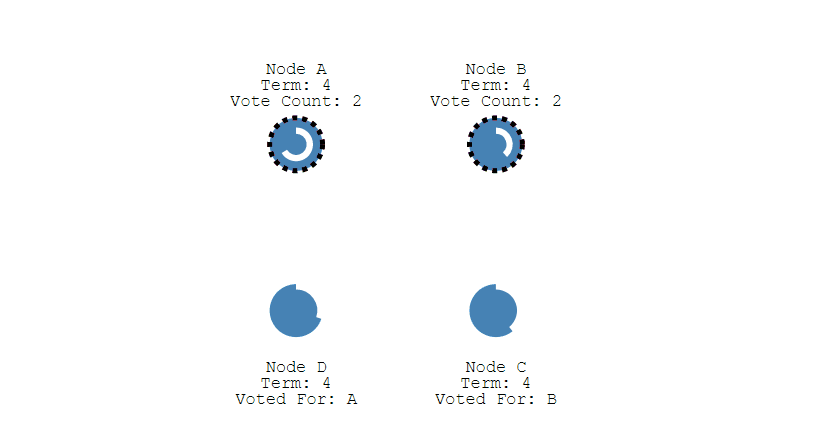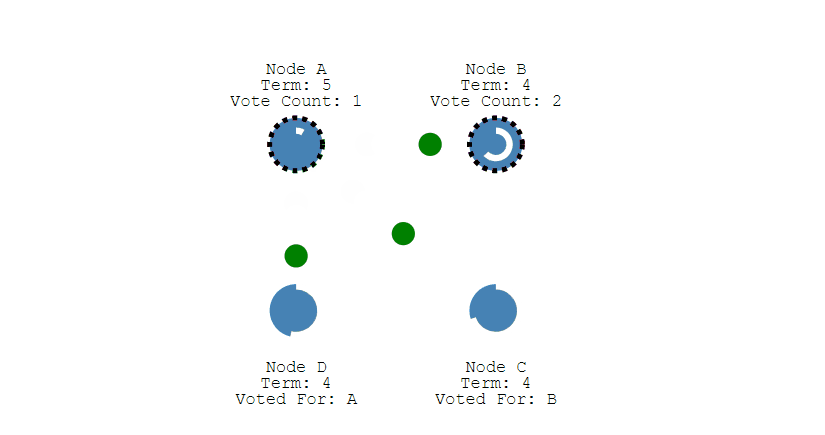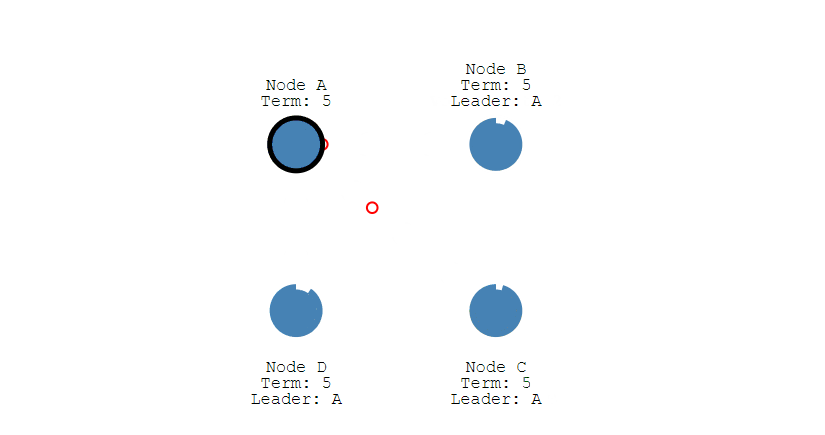
第三步,收到投票请求并且还未投票的Follower节点会向发起者回复投票反馈,如果收到了超过半数的回复,此时Candidate选举成功,状态转变为Leader。
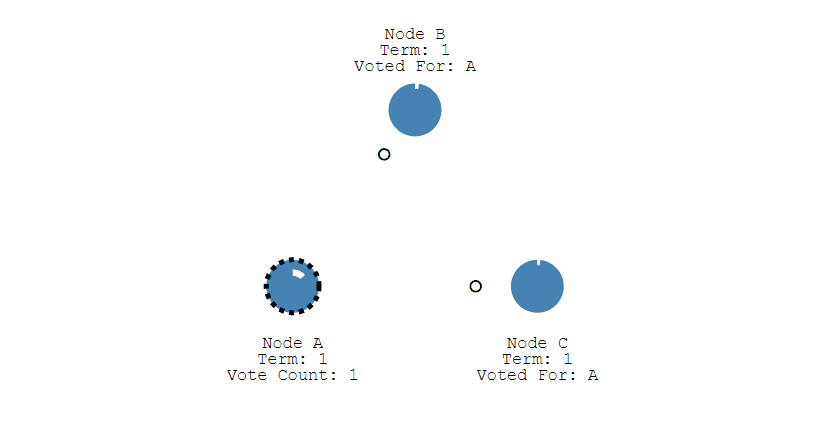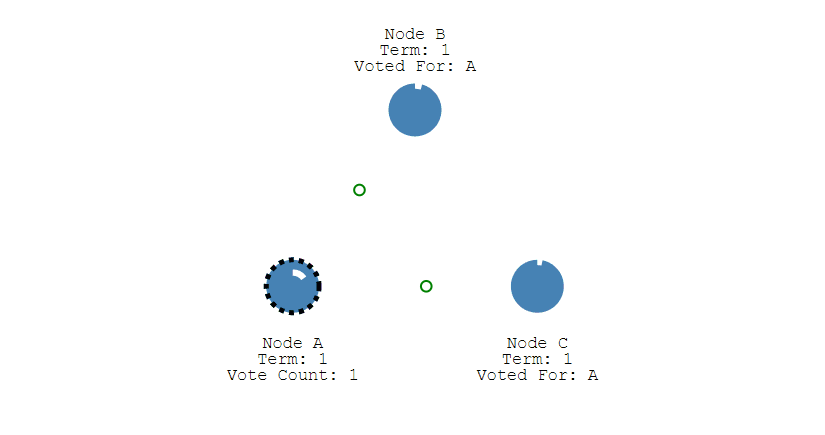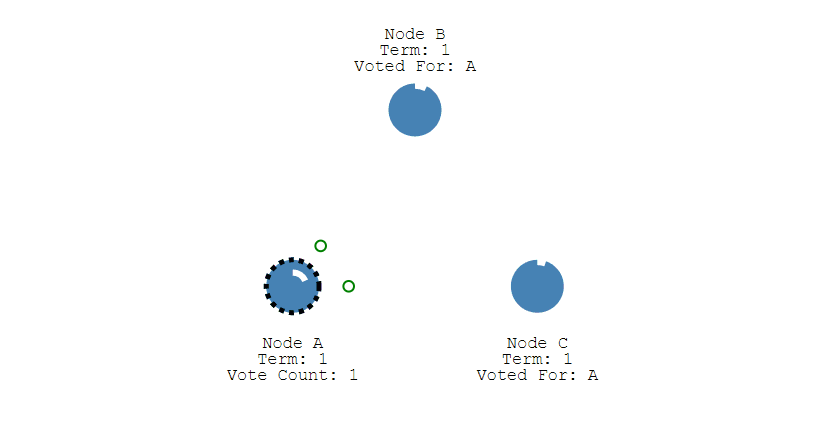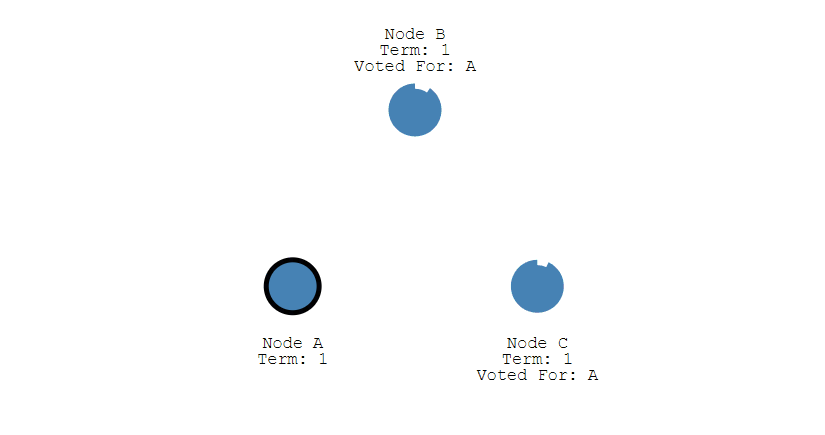
第四步,Leader节点会立刻向其他节点发出通告,告知其他节点它已成功选举成Leader,收到通知的节点会转换为Follower。并且Leader会周期性的发送心跳包给所有Follower来表明它还存活,当Follower接收到心跳包时,就会重置计时器。
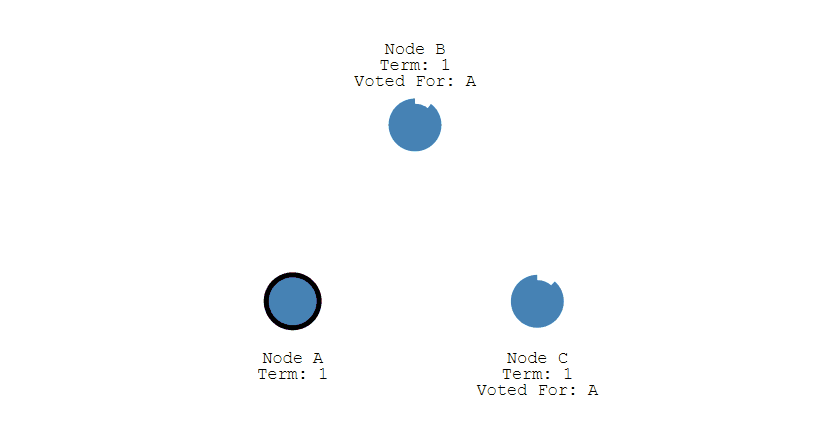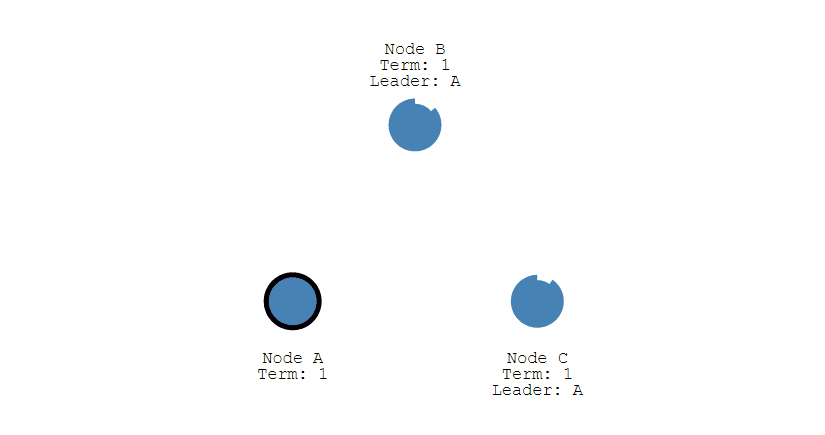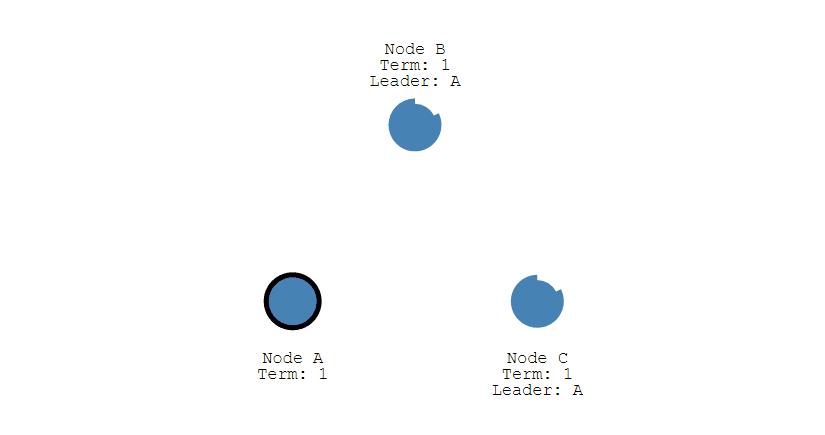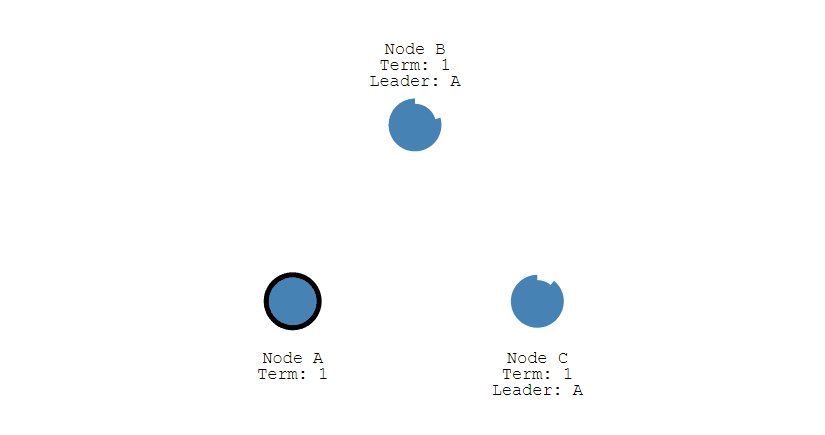
一旦Leader节点挂掉,它就无法发出心跳包来重置Follower的倒计时器,那么当Follower的超时时间到达后,其就会转换成Candidate节点,再次重复以上过程。
上面介绍的是单节点的选举,倘若同时有多个Follower同时倒计时结束后成为Candidate,同时开始选举,并且在选举过程中所获得的票数相同,此时就陷入了僵局,谁都无法成为Leader。
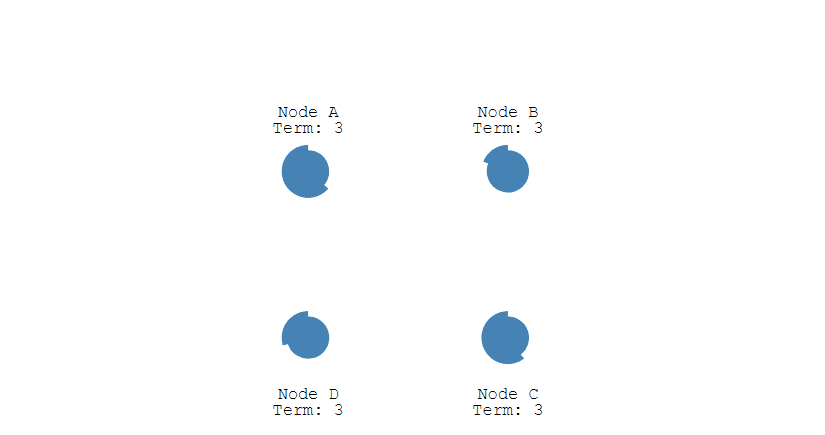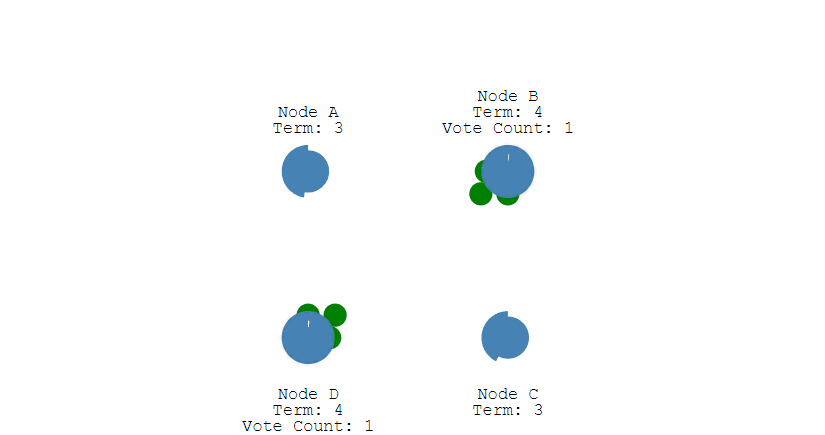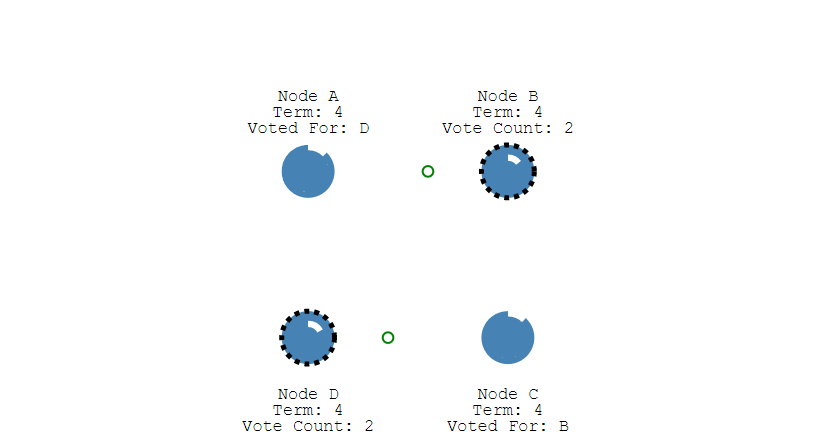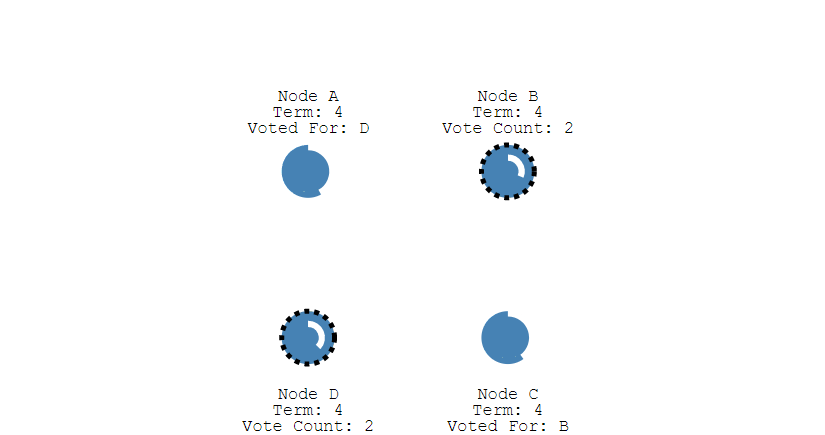
在重新选举时,由于每个节点设置的超时时间都是随机的,因此下一次同时出现多个Candidate并获得同样票数导致选举失败的情况的概率则非常低。
数据同步
Raft中数据同步的方式与之前写过的2PC(二阶段提交协议)有一些相似,也是分为投票和提交两个阶段,具体流程如下。
第一步,客户端将修改传入Leader中(此时修改并没有提交,只是写入日志中)。
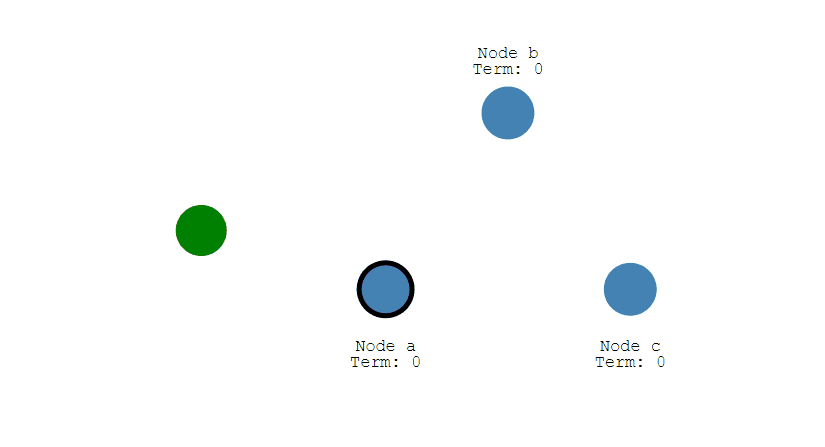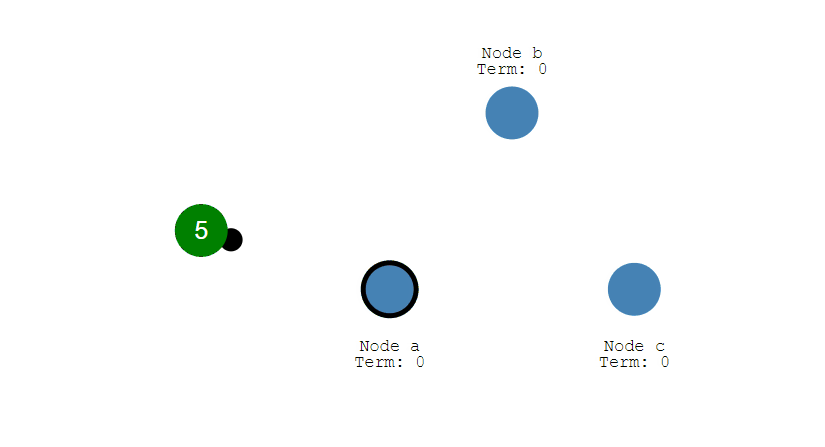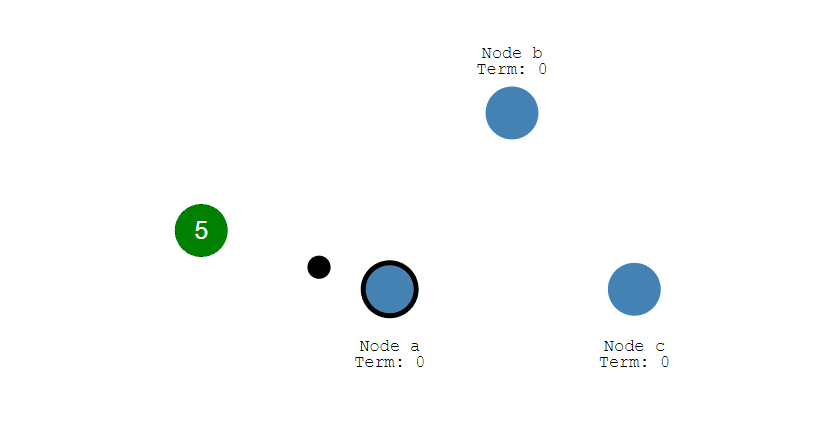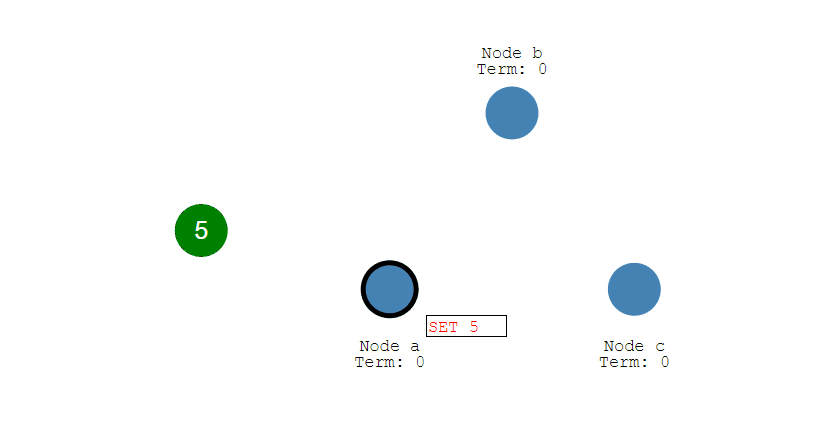
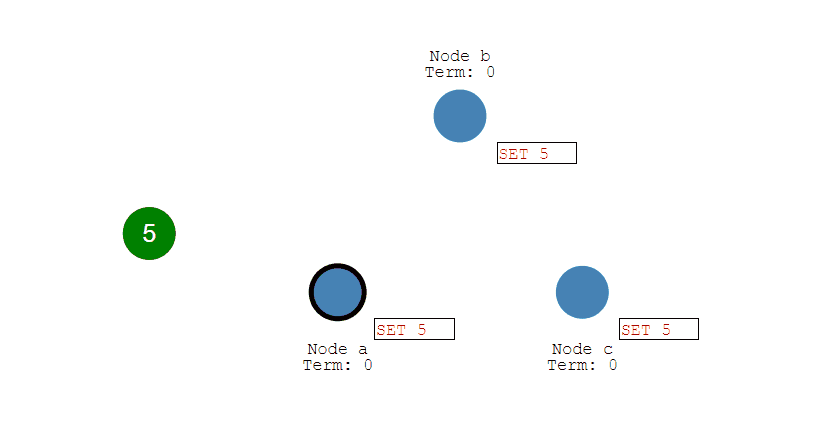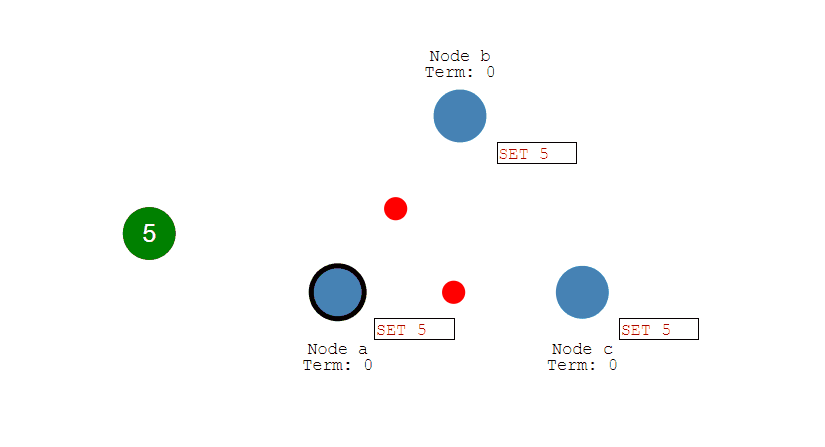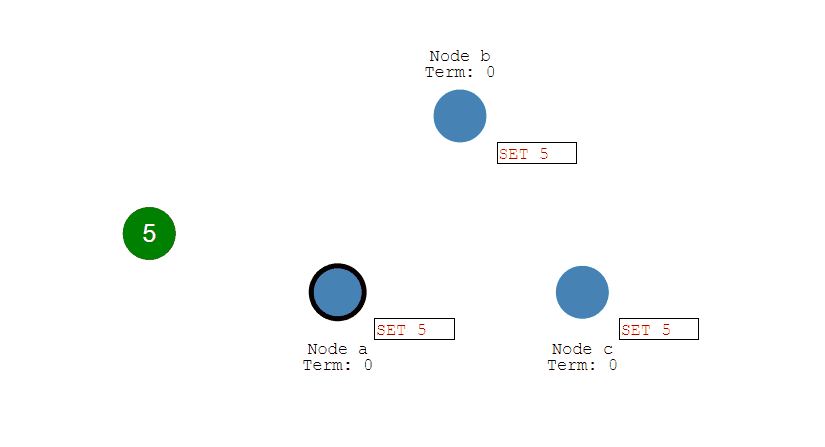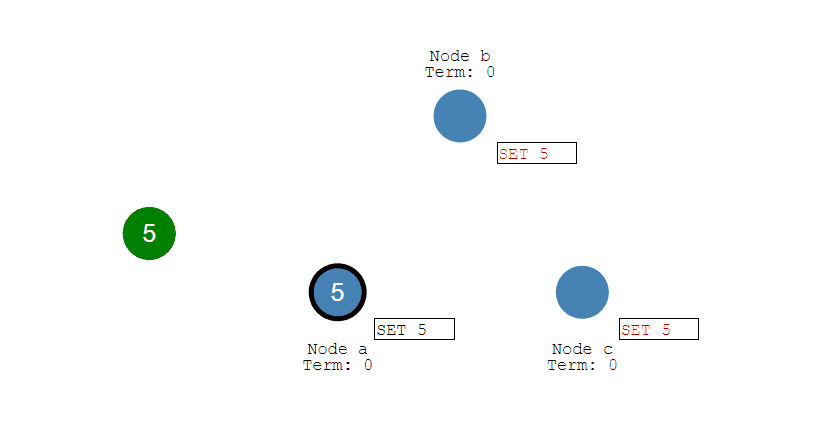
第二步,Leader将修改复制到集群内的所有Follower节点上,如果复制失败,会不断进行重试直至成功。
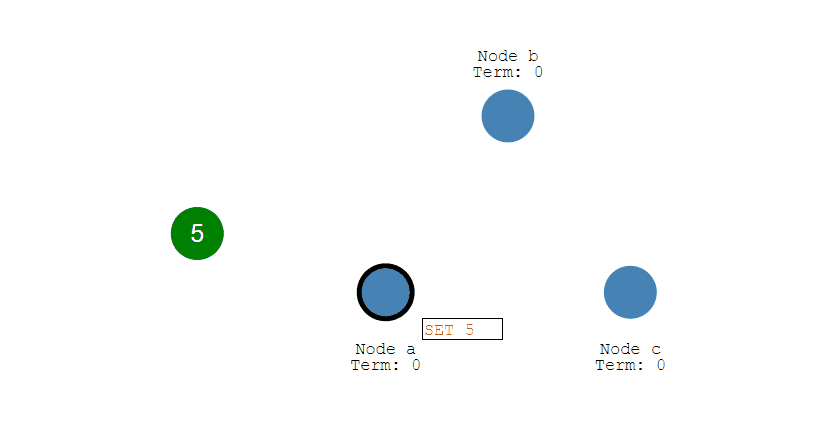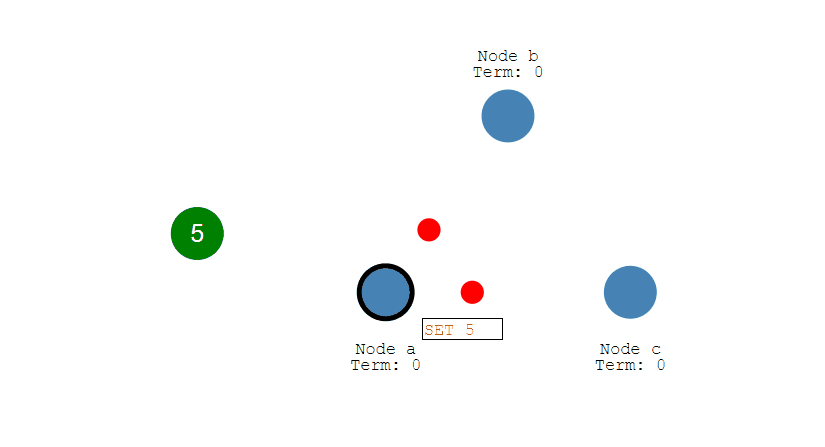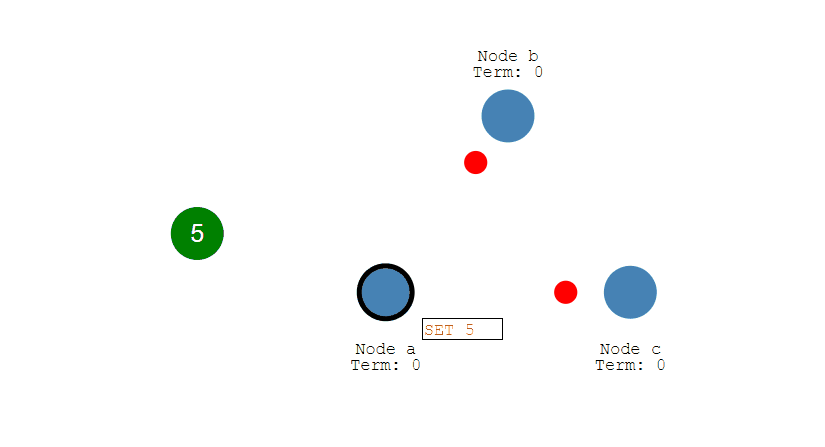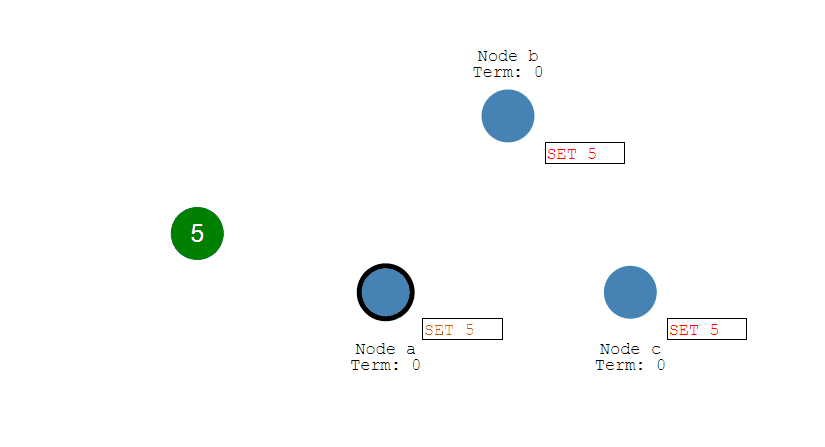
第三步,Follow节点们成功接收到复制的数据后,会反馈结果给Leader节点,如果Leader节点接收到超过半数的Follower反馈,则表明复制成功,于是提交自己的数据,并且通知客户端数据提交成功。
第四步,提交成功后,Leader会通知所有的Follower让它们也提交修改,此时所有节点的值达成一致,完成数据同步流程。
为了便于理解,可以结合下面的Raft原理动画一同学习。