一致性哈希
分布式存储
如果我们需要存储QQ号与个人信息,建立起<QQ, 个人信息>的KV模型。
假设QQ有10亿用户,并且每个用户的个人信息占据了100M,如果要存储这些数据,所需要的空间就得(100亿* 100M) = 10WT,这么庞大的数据是不可能在单机环境下存储的,只能采用分布式的方法,用多个机器进行存储,但是即使使用多机,这些数据也至少要10w台机器(假设每台服务器存1T)才能存储。
并且我们还需要考虑,如何将这10w台机器与我们的数据建立起映射关系呢? 换句话来说就是,我们如何确定哪些数据应该放在哪个机器呢?这时就需要用到哈希算法。
简单哈希
我们可以采用除留余数法来完成一个映射,key值为qq号,余数为机器数量,得到的结果就是应该存储的机器的编号。这样我们将数据放入指定机器中,使用时再根据机器号进入对应的机器进行增删查改即可。
|
|
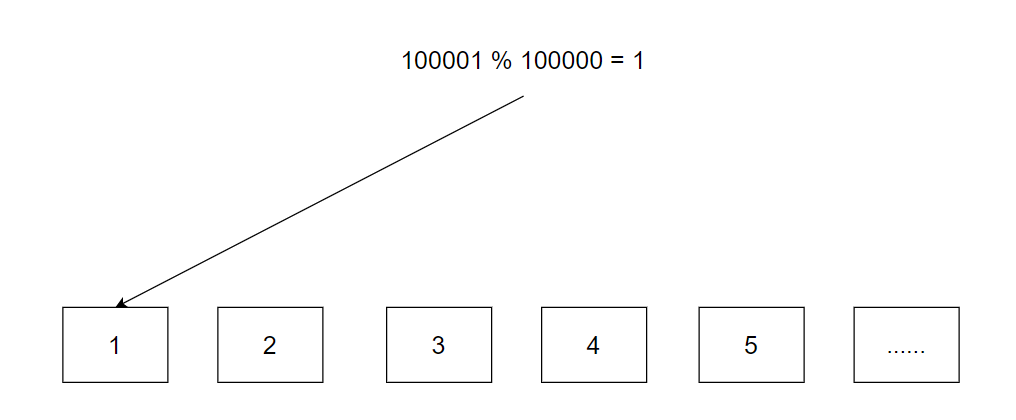
但是这个方法存在着一个致命的缺陷,随着用户量不断增多或者用户信息增加,10w台机器就会不够用,此时就需要将机器扩容至15w台。 当进行扩容后,由于机器数量发生变化,数据的映射关系也会变化,我们就需要进行rehash来将数据重新映射到正确的位置上。
但是问题来了,这10w台机器的数据如果需要进行重新映射,花费的时间几乎是不可想象的,我们不可能说为了迁移数据而让服务器宕机数月之久,所以这种方法是不可能行得通的。
一致性哈希
为了弥补上一种方法的,就引入了一致性哈希算法。
上面一种方法的主要缺陷就是由于扩容后rehash带来的数据大量迁移问题。
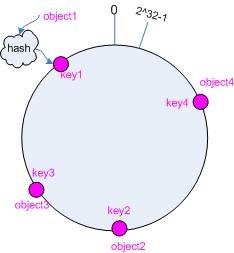 为了解决上述问题,一致性哈希将哈希构造成一个0~2^32-1的环形结构,并将余数从原来的机器数量修改值为整型最大值(也可以是比这个更大的)。因为这个数据足够大,所以不需要考虑因为机器数增加导致的rehash问题。
为了解决上述问题,一致性哈希将哈希构造成一个0~2^32-1的环形结构,并将余数从原来的机器数量修改值为整型最大值(也可以是比这个更大的)。因为这个数据足够大,所以不需要考虑因为机器数增加导致的rehash问题。
|
|
我们将环中的某一区间去映射到某台服务器,让这台服务器负责这个区间的管理,这样就能让这10w台服务器来切分这个闭环结构
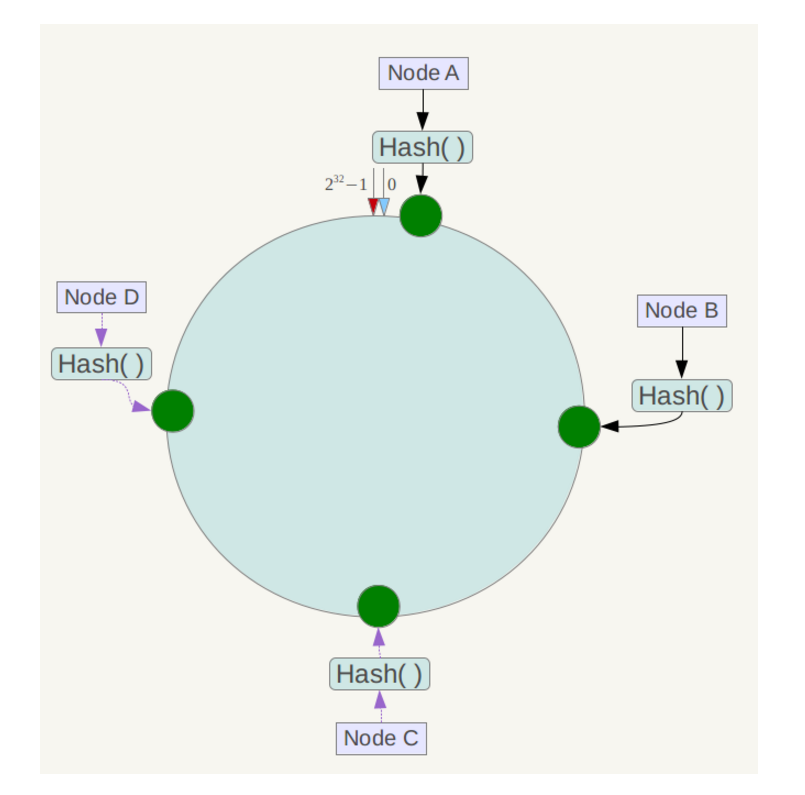 当我们要查询某个数据的时候,根据哈希函数算出的映射位置来找到包含该位置的那个区间所对应的服务器,然后在那个服务器中进行操作即可
当我们要查询某个数据的时候,根据哈希函数算出的映射位置来找到包含该位置的那个区间所对应的服务器,然后在那个服务器中进行操作即可
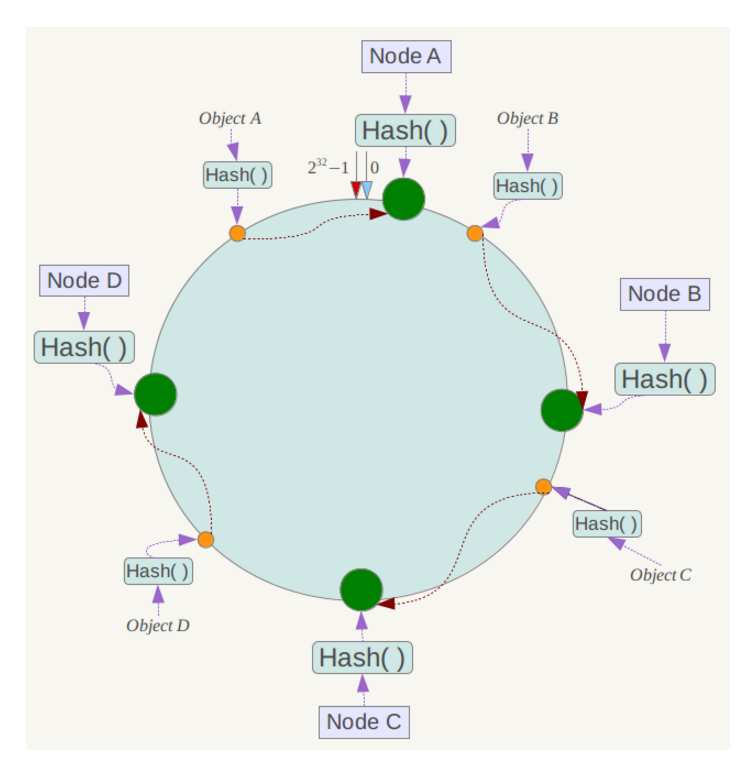 如果原先的服务器不够用了,此时增加5w个服务器,也不需要像之前一样对所有机器的数据进行迁移,我们只需要迁移负载重的机器即可
如果原先的服务器不够用了,此时增加5w个服务器,也不需要像之前一样对所有机器的数据进行迁移,我们只需要迁移负载重的机器即可
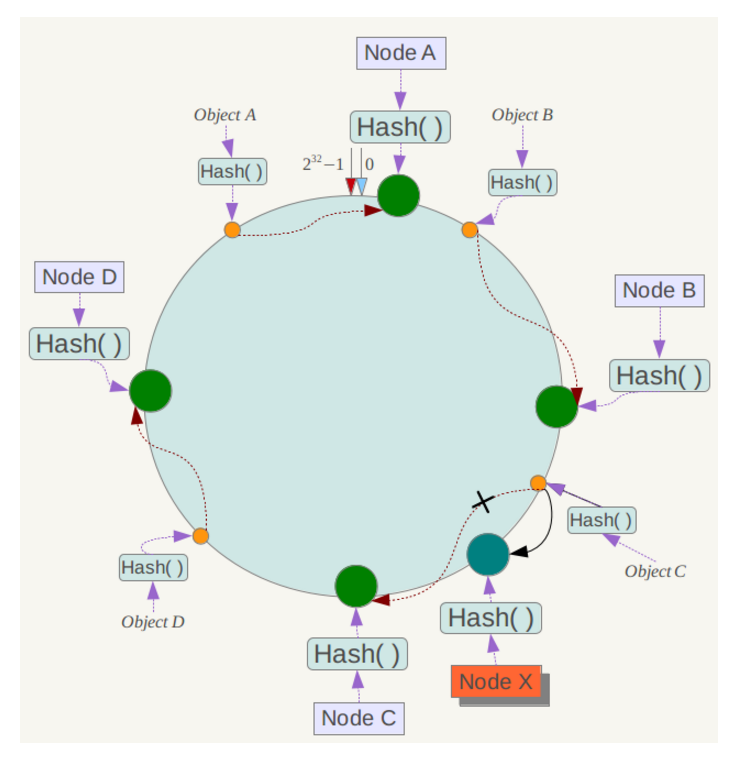
例如此时NodeC中存储了25000-50000的数据,此时往其中增加一个新服务器NodeE,让其负责映射闭环中25000-37500的数据。 此时我们需要做的就是将NodeC中25000~37500的那一部分重新迁移到NodeE上,并改变两个服务器的映射范围,就完成了数据的迁移。从这里我们可以看到,一致性哈希将服务器数据的整体迁移变成了高负载服务器的部分迁移,大大提高了效率以及稳定性。
总结: 一致性哈希就是一个大范围的闭环,由于除数过大,我们也不需要因为由于除数增加导致全体rehash。并且映射关系变味了数据区间——机器,如果要增加机器,就只需要改变映射范围,并将区间中的小部分数据进行迁移,大大的提高了效率。
虚拟节点
但是,一致性哈希也存在缺陷,就是在节点过少的时候可能会因为节点分布不均匀而导致数据倾斜问题。例如当前只有两个服务器
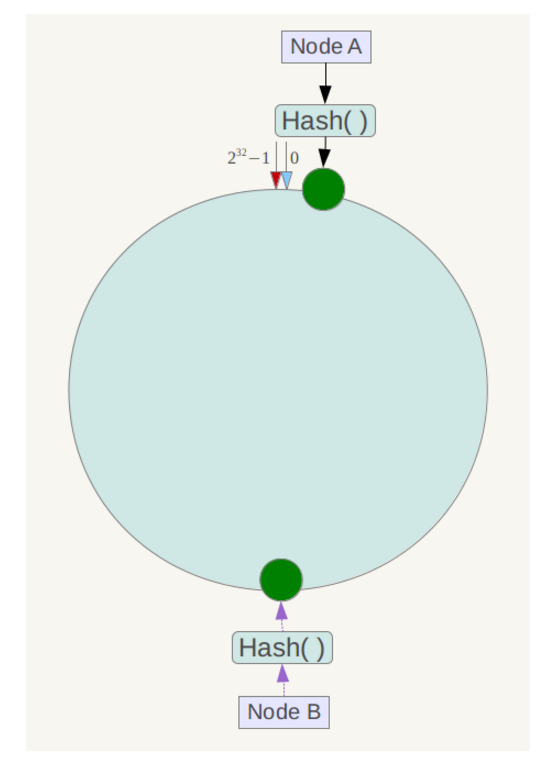 此时就会出现这种情况,部分节点数据过少,而部分节点数据过多,此时的数据大量集中在NodeA上,数据大量倾斜。
此时就会出现这种情况,部分节点数据过少,而部分节点数据过多,此时的数据大量集中在NodeA上,数据大量倾斜。
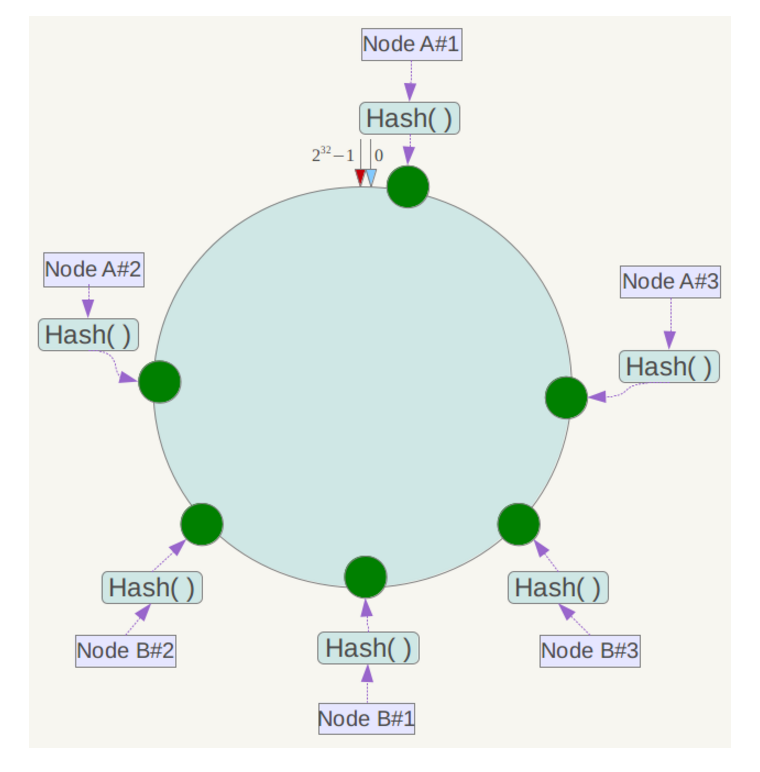 既然节点较少,那就可以考虑在不增加服务器的基础上多增加几个节点,所以为了解决这问题,一致性哈希又引入了虚拟节点。对每个服务节点进行多次哈希映射,每个映射的位置都会放置该服务节点,成为虚拟节点。例如上图,就分别将NodeA和NodeB分成了三个虚拟节点。我们不需要改变数据定位的算法,只需要将虚拟节点与服务节点进行映射,将定位到虚拟节点NodeX #1、#2、#3的节点再定位回服务节点即可。
既然节点较少,那就可以考虑在不增加服务器的基础上多增加几个节点,所以为了解决这问题,一致性哈希又引入了虚拟节点。对每个服务节点进行多次哈希映射,每个映射的位置都会放置该服务节点,成为虚拟节点。例如上图,就分别将NodeA和NodeB分成了三个虚拟节点。我们不需要改变数据定位的算法,只需要将虚拟节点与服务节点进行映射,将定位到虚拟节点NodeX #1、#2、#3的节点再定位回服务节点即可。
通过这种方法就保证了即使服务节点少,也能做到相对均匀的数据分布