分布式文件系统
基本概念
分布式文件系统(Distributed File System)是网络文件系统的延伸,其关键点在于存储端可以灵活地横向扩展。也就是可以通过增加设备(主要是服务器)数量的方法来扩充存储系统的容量和性能。同时,分布式文件系统还要对客户端提供统一的视图。也就是说,虽然分布式文件系统服务由多个节点构成,但客户端并不感知。在客户端来看就好像只有一个节点提供服务,而且是一个统一的分布式文件系统。
分布式文件系统 VS 网络文件系统
从本质上来说,分布式文件系统其实也是网络文件系统的一种,其与网络文件系统的差异在于服务端包含多个节点,也就是服务端是可以横向扩展的,其可以通过增加节点的方式增加文件系统的容量,提升性能。
由于其数据被存储在多个节点上,因此还有其他特点:
- 支持按照既定策略在多个节点上放置数据。
- 可以保证在出现硬件故障时,仍然可以访问数据。
- 可以保证在出现硬件故障时,不丢失数据。
- 可以在硬件故障恢复时,保证数据的同步。
- 可以保证多个节点访问的数据一致性。
横向拓展结构
对于存储集群端主要有两种类型的架构模式:一种是以有中心控制节点的分布式架构,另一种是对等的分布式架构,也就是没有中心控制节点的架构。
中心架构
中心架构是指在存储集群中有一个或多个中心节点,中心节点维护整个文件系统的元数据,为客户端提供统一的命名空间。 在实际生产环境中,中心节点通常是多于一个的,其主要目的是保证系统的可用性和可靠性。
在中心架构中,集群节点的角色分为两种:
- 控制节点:这种类型的节点会存储文件系统的元数据信息,并对请求进行协调与处理,根据元数据将请求转发只对应的节点上。
- 数据节点:这种类型的节点用于存储文件系统的用户数据。
架构示意图如下:
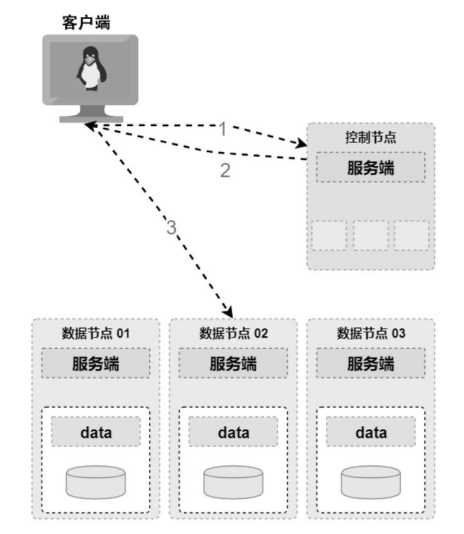
当客户端需要对一个文件进行读/写时,首先会访问控制节点,控制节点通过对一些元数据进行处理(鉴权、文件锁、位置计算等),并将文件所在的数据节点的位置响应给客户端。此时客户端再与数据节点交互,完成数据的访问。
对等架构
对等架构是没有中心节点的架构,集群中并没有一个特定的节点负责文件系统元数据的管理。在集群中所有节点既是元数据节点,也是数据节点。 在实际实现中,其实并不进行角色的划分,只是作为一个普通的存储节点。
由于在对等架构中没有中心节点,因此主要需要解决两个问题:
- 客户端需要一种位置计算算法来计算数据应该存储的位置。
- 需要将元数据存储在各个存储节点,在某些情况下需要客户端来汇总。
关键原理
分布式文件系统本身也是文件系统,因此它与本地文件系统和网络文件系统等具备一些公共技术。除此之外,鉴于其分布式的特点,还涉及一些分布式的技术。
数据布局
分布式文件系统的数据布局与本地文件系统不同,其关注的不是数据在磁盘的布局,而是数据在存储集群各个节点的放置问题。
在分布式文件系统中,数据布局解决的主要问题是性能和负载均衡的问题。其解决方案就是通过多个节点来均摊客户端的负载,也就是实现存储集群的横向扩展。因此数据布局的核心,就是要保证数据量均衡与负载均衡。
基于动态监测的数据布局
基于动态监测的数据布局是指通过监测存储集群各个节点的负载、存储容量和网络带宽等系统信息来决定新数据放置的位置。 另外,集群节点之间还要有一些心跳信息,这样当有数据节点故障的情况下,控制节点可以及时发现,保证在决策时剔除。
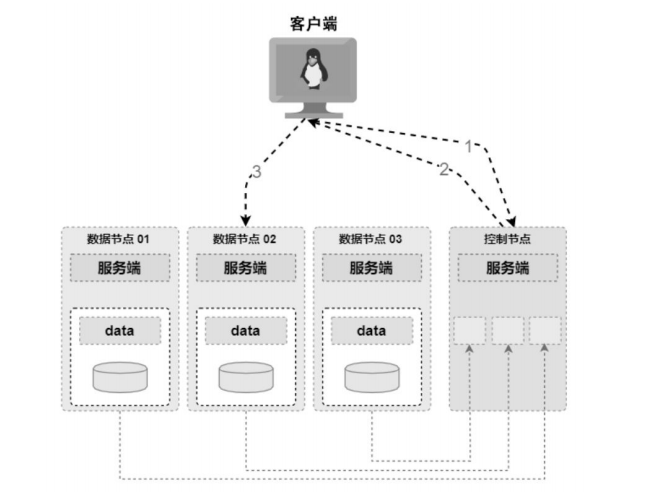
由于需要汇总各个节点的信息进行决策,因此基于动态监测的数据布局通常需要一个中心节点。中心节点负责汇总各种信息并进行决策,并且会记录数据的位置信息等元数据信息。当客户端需要写入数据时,客户端首先与控制节点交互;控制节点根据汇总的信息计算出新数据的位置,然后反馈给客户端;客户端根据位置信息,直接与对应的数据节点交互。
基于计算位置的数据布局
基于计算位置的数据布局是一种固定的数据分配方式。在该架构中通过一个算法来计算文件或数据存储的具体位置。 当客户端要访问某个文件时,请求在客户端或经过的某个代理节点计算出数据的具体位置,然后将请求路由到该节点进行处理。
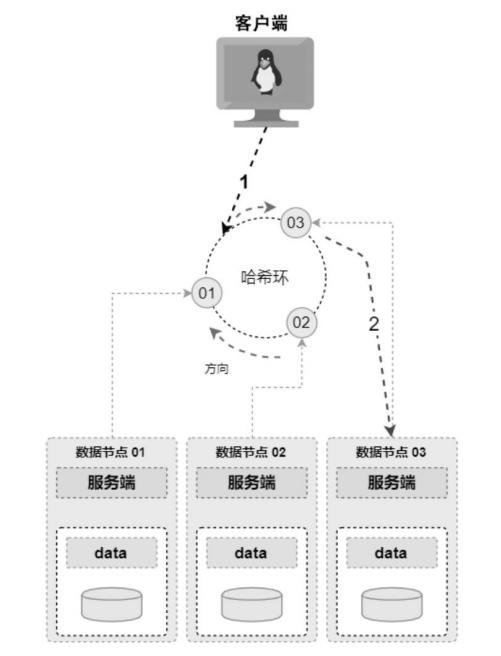
当客户端访问集群数据时,首先计算出数据的位置(根据请求的特征来计算数据具体应该放到哪个节点,例如一致性哈希算法),然后与该节点交互。
数据可靠性
分布式数据的可靠性是指在出现组件故障的情况下依然能够能提供正常服务的能力。
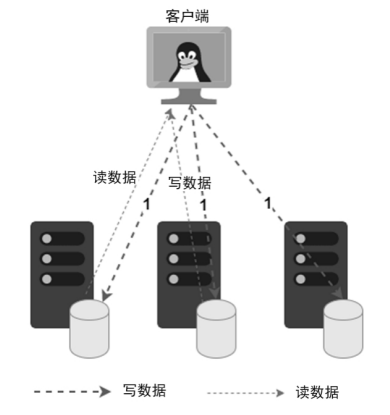
复制(Replication)
复制技术是通过将数据复制到多个节点的方式来实现系统的高可靠。 由于同一份数据会被复制到多个节点,这样同一个数据就存在多个副本,因此也称为多副本技术,这样当出现节点故障时就不会影响数据的完整性和可访问性。
复制技术有两种不同的模式:
-
主从节点复制:即在副本节点中有一个节点是主节点,所有的数据请求先经过主节点。对于一个写数据请求,客户端将请求发送到主节点,主节点将数据复制到从节点,再给客户端应答。
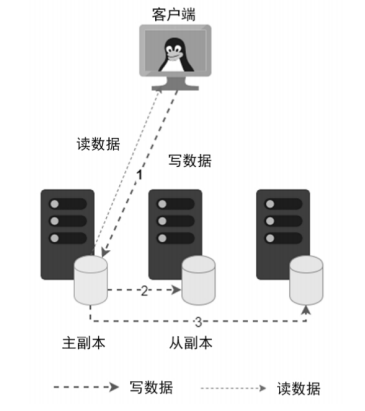
-
无主节点复制:即在集群端并没有一个主节点,副本逻辑在客户端或代理层完成。 当客户端发送一个写数据请求时,客户端会根据策略自行(或者通过代理层)找到副本服务器,并将多个副本发送到副本服务器上。
纠删码(Erasure Code)
副本技术的本质就是冗余存储,因此需要消耗很多额外的存储空间。以 3 个副本为例,需要额外消耗 2 倍的存储空间来保证数据的可靠性。虽然副本技术在性能和可靠性方面优势明显,但成本明显比较高。为了降低存储的成本,很多公司采用纠删码技术来保证数据的可靠性。
纠删码是一种通过校验数据来保证数据可靠性的技术,也就是该技术通过保存额外的一个或多个校验块来提供数据冗余。与副本技术不同,这种数据冗余技术不能通过简单复制来恢复数据,而是经过计算来得到丢失的数据。
纠删码的基本原理是采用矩阵运算,将 n 个数据转换为 n+m 个数据进行存储。其基本流程如下:
- 校验数据生成:找到一个生成矩阵,通过该矩阵与原始数据的运算可以得到最终要存储的校验数据。
- 数据恢复:由于生成矩阵是可逆的,因此可利用生成矩阵和剩余可用数据来计算出原始数据。
数据一致性
在分布式文件系统中,由于同一个数据块被放置在不同的节点上,我们无法保证多个节点的数据时时刻刻是相同的,因此会出现一致性的问题。这里的一致性包括两个方面:一个方面是各个节点数据的一致性问题;另一个方面是从客户端访问角度一致性的问题。
通常来说,我们是无法保证各个节点上数据是完全一致的(故障、宕机、延迟、网络分区等原因),只能保证客户端访问的一致性。为了保证客户端访问数据的一致性,通常需要对存储系统进行特殊的设计,从而在系统层面保证数据的一致性。通常提供的一致性保证有如下两种:
- 强一致性:当数据的写入操作反馈给客户端后,任何对该数据的读操作都会读到刚刚写入的数据。
- 最终一致性:在执行一个写入操作后,如果没有新的写入操作的情况下, 该写入的数据会最终同步到所有副本节点上,但中间会有时间窗口。
故障与容错
在分布式文件系统中必须要解决设备故障的问题。这是因为在大规模分布式文件系统中设备的总量达到数万个甚至数十万个,设备发生故障就会成为常态。
设备的故障分为两种类型:
- 临时故障:指短时间可以恢复的故障,如服务器重启、网线松动或交换机掉电等。
- 永久故障:指设备下线,且永远不会恢复,如硬盘损坏等。
为了应对系统随时出现的故障,分布式文件系统在设计时必须要考虑容错处理。容错主要包括以下几方面内容:
- 故障预测:在故障发生前,预知设备故障,然后有计划地将该设备下线,避免突然下线导致的性能等问题。
- 故障检测:在故障发生时,及时发现故障原因,方便进行问题的修复。如检测磁盘、通信链路或服务的故障等。
- 故障恢复:在故障发生后,快速进行响应,保证系统仍然能够对外提供无损的服务。如通过部件冗余、主备链路等。当系统发生故障时,可以通过切换链路,或者通过冗余节点来提供服务。