分布式时钟
逻辑时钟与物理时钟
对于分布式系统来说,时钟分为逻辑时钟与物理时钟两种。物理时钟对应的是我们真实世界的时间,一般由操作系统提供,而逻辑时钟则一般被实现为一个单调递增的计数器。
为什么在分布式系统中不直接使用物理时钟,而是使用逻辑时钟呢?
对于分布式系统而言,即使我们可以使用一些工具去同步集群内的时间,但是使所有节点的时间保持一致这个目标依旧是很难达成的。而如果我们使用不同节点产生的不一致的物理时间来进行一致性计算,就会导致结果出现很大的偏差,因此分布式系统就通过另外的方法来记录事件的顺序关系,也就是上面提到的逻辑时间。
如何实现逻辑时钟?
Lamport timestamps
Leslie Lamport 在1978年提出逻辑时钟的概念,并描述了一种逻辑时钟的表示方法,这个方法被称为 Lamport 时间戳(Lamport timestamps)。
分布式系统中按是否存在节点交互可分为三类事件,一类发生于节点内部,二是发送事件,三是接收事件。Lamport 时间戳原理如下图:
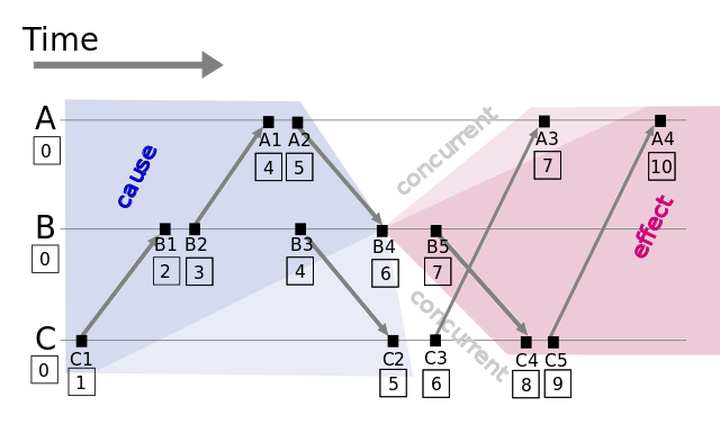
- 每个事件对应一个 Lamport 时间戳,初始值为0
- 如果事件在节点内发生,时间戳加1
- 如果事件属于发送事件,时间戳加1并在消息中带上该时间戳
- 如果事件属于接收事件,时间戳 = Max(本地时间戳,消息中的时间戳) + 1
假设有事件 a、b,C(a)、C(b )分别表示事件 a、b 对应的 Lamport 时间戳,如果 a 发生在b 之前,记作 a⇒b,则有C(a)<C(b),例如图1中有 C1→B1,那么 C(C1)<C(B1)。通过该定义,事件集中 Lamport 时间戳不等的事件可进行比较,我们获得事件的偏序关系(partial order)。注意:如果C(a)<C(b),并不能说明a⇒b,也就是说C(a)<C(b是a⇒b的必要不充分条件
如果 C(a) = C(b),那a、b事件的顺序又是怎样的?值得注意的是当 C(a) = C(b)的时候,它们肯定没有因果关系,所以它们之间的先后顺序其实并不会影响结果,我们这里只需要给出一种确定的方式来定义它们之间的先后就能得到全序关系。注意:Lamport逻辑时钟只保证因果关系(偏序)的正确性,不保证绝对时序的正确性。
通过以上定义,我们可以对所有事件排序,获得事件的全序关系。以上图例子,我们可以进行排序: C1 ⇒ B1 ⇒ B2 ⇒ A1 ⇒ B3 ⇒ A2 ⇒ C2 ⇒ B4 ⇒ C3 ⇒ A3 ⇒ B5 ⇒ C4 ⇒ C5 ⇒ A4
观察上面的全序关系你可以发现,从时间轴来看 B5 是早于 A3 发生的,但是在全序关系里面我们根据上面的定义给出的却是 A3 早于 B5,可以发现 Lamport 逻辑时钟是一个正确的算法,即有因果关系的事件时序不会错,但并不是一个公平的算法,即没有因果关系的事件时序不一定符合实际情况。
Vector clock
因此 Vector clock 就在 Lamport timestamps 的基础上加以改进,它通过 vector 结构记录了本节点与其他节点的 Lamport timestamps。其原理如下图
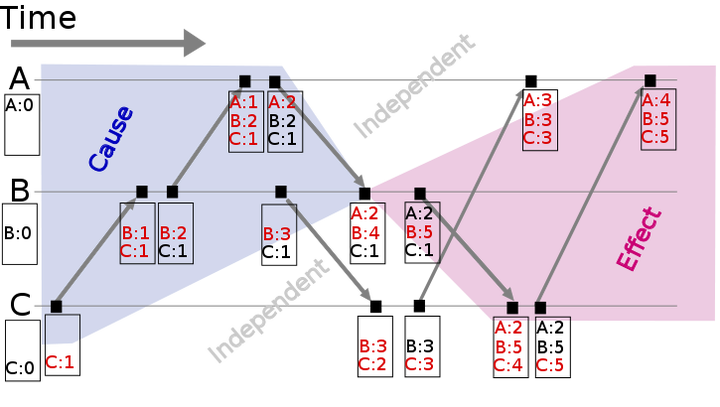
从上图可以看出,Vector clock 与 Lamport timestamps 的规则几乎一模一样。
假设有事件 a、b 分别在节点 P、Q 上发生,Vector clock 分别为 Ta、Tb,如果 Tb[Q] > Ta[Q] 并且 Tb[P] >= Ta[P],则a发生于b之前,记作a⇒b。到目前为止还和 Lamport timestamps 差别不大,那 Vector clock 怎么判别同时发生关系呢?
如果 Tb[Q] > Ta[Q] 并且 Tb[P] < Ta[P],则认为 a、b 同时发生,记作 a <=> b。例如图 2 中节点 B 上的第4 个事件 (A:2,B:4,C:1) 与节点 C 上的第 2 个事件 (B:3,C:2) 没有因果关系、属于同时发生事件。
Version vector
基于 Vector clock 我们可以获得任意两个事件的顺序关系,或为先后顺序或为同时发生,识别事件顺序在工程实践中有很重要的引申应用,最常见的应用是发现数据冲突。这时,就诞生了 Version vector。
分布式系统中为了保证可用性,数据往往存在多个副本,而这多个副本又可能会被同时更新,这就会导致副本之间产生数据不一致的情况。Version vector 的目的就是为了发现这些数据冲突,其实现与 Vector clock类似,下图则是其具体运作流程。
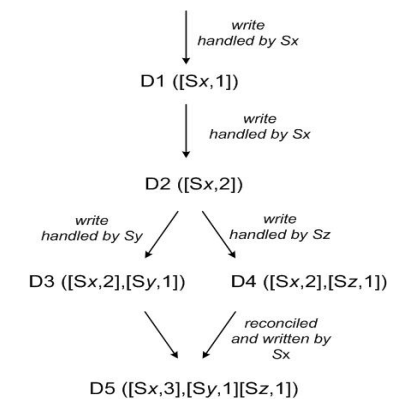
- client端写入数据,该请求被Sx处理并创建相应的 vector ([Sx, 1]),记为数据 D1
- 第 2 次请求也被 Sx 处理,数据修改为 D2,vector 修改为 ([Sx, 2])
- 第 3、第 4 次请求分别被 Sy、Sz 处理,client 端先读取到 D2,然后 D3、D4 被写入 Sy、Sz
- 第 5 次更新时 client 端读取到 D2、D3和D4 3个数据版本,通过类似 Vector clock 判断同时发生关系的方法可判断 D3、D4 存在数据冲突,最终通过一定方法解决数据冲突并写入 D5
Vector clock只用于发现数据冲突,不能解决数据冲突。解决数据冲突因场景而异,具体方法有以最后更新为准(last write win),或将冲突的数据交给client由client端决定如何处理,或通过quorum决议事先避免数据冲突的情况发生。
由于记录了所有数据在所有节点上的逻辑时钟信息,Vector clock 和 Version vector 在实际应用中可能面临的一个问题是 vector 过大,用于数据管理的元数据甚至大于数据本身。
解决该问题的方法是使用 server id 取代 client id 创建 vector (因为 server 的数量相对 client 稳定),或设定最大的 size、如果超过该 size 值则淘汰最旧的 vector 信息。