数据模型与查询语言
关系模型与文档模型
现在最著名的数据模型可能是 SQL ,它基于 Edgar Codd 在 1970 年提出的关系模型: 数据被组织成关系(在 SQL 中称为表),其中每个关系都是元组的无序集合(SQL 中称为行)。
关系模型的目标就是将实现细节隐藏在更简洁的接口后面。
NoSQL的诞生
NoSQL最常见的解释是 Non-Relationa,而如今又使用 Not Only SQL 来对其进行解释。NoSQL 其实并不代表具体的某些技术,它仅仅是一个概念,泛指非关系型的数据库,区别于关系数据库,它们不保证关系数据的ACID特性。
采用 NoSQL 数据库有这样几个驱动因素 ,包括:
- 比关系数据库更好的扩展性需求,包括支持超大数据集或超高写入吞吐量。
- 普遍偏爱免费和开源软件而不是商业数据库产品。
- 关系模型不能很好地支持一些特定的查询操作。
- 对关系模式一些限制性感到沮丧,渴望更具动态和表达力数据模型。
对象-关系不匹配
如今大多数应用开发都采用面向对象的编程语言,由于兼容性问题,普遍对 SQL 数据模型存在抱怨:如果数据存储在关系表中,那么应用层代码中的对象与表、行和列的数据库模型之间需要一个笨拙的转换层。这种模型之间的脱离被称为阻抗失谐。
像 ActiveRecord 和 Hibernate 这样的对象关系映射(ORM,Object-Relational Mapping) 框架减少了此转换 层的样板代码 ,但是他们并不能完全隐藏两个模型之间的差异。
例如我们使用关系模型来描述一个简历:
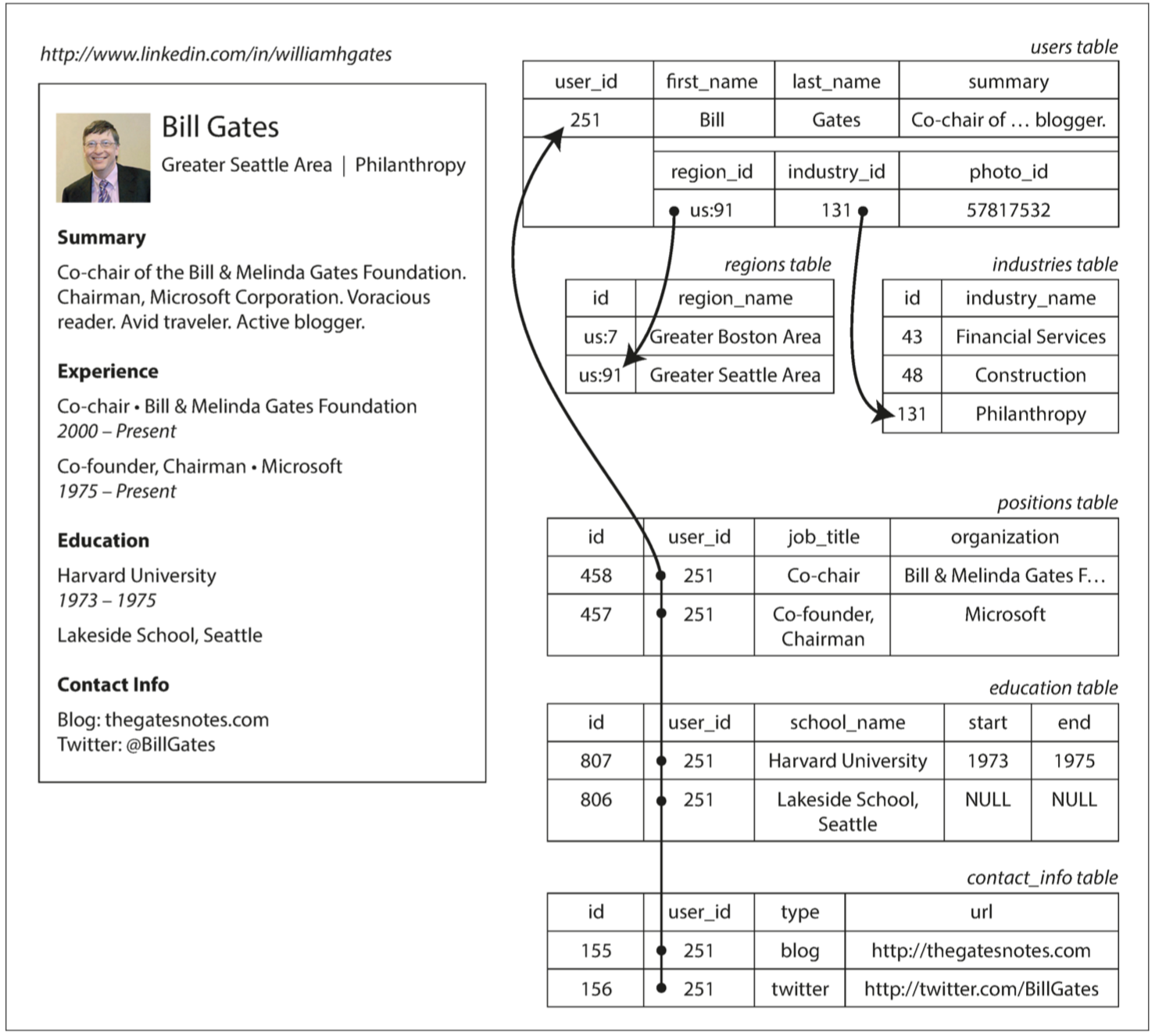
对于简历这种用户与经历这种一对多的关系,我们可以用多种方法表示:
- 传统的 SQL 模型,将职位、教育和联系信息放在单独的表中并使用外键引用 users 表。
- SQL 标准增加了对结构化数据类型和 XML 数据的支持。这允许将多值数据存储在单行,井支持在这些文档中查询和索引。
- 将信息编码为 JSON、XML 文档,将其存储在数据库的文本列中,并由应用程序解释其结构和内容。
对于像简历这样的数据结构,它主要是一个自包含的文档,因此用 JSON 表示更加合适。代码如下:
|
|
JSON 模型减少了应用程序代码和存储层之间的阻抗失配,并且其比起关系模式的多表查询具有更好的局部性,其所有的相关信息都在一个地方,所以一次查询就足够了,因此大部分文档数据库都支持这种模型。
数据模型
层次模型
层次模型与文档数据库使用的 JSON 模型有一些显著的相似之处。它将所有数据表示为嵌套在记录中的记录(树)。
层次模型可以很好地支持一对多关系,但是它支持多对多关系则有些困难,而且不支持联结。开发人员必须决定是复制(反规范化)多份数据,还是手动解析记录之间的引用。
为了解决层次模型的局限性,之后又提出了多种解决方案。其中最著名的是关系模型(relational model)和网络模型(network model)。
网络模型
网络模型由一个称为数据系统语言会议(Conference on Data System Languages, CODASYL)的委员会进行标准化,井由多个不同的数据库厂商实施,它也被称为 CODASYL 模型。
网络模型是层次模型的推广。在层次模型的树结构中,每个记录只有一个父节点;而在网络模型中, 一个记录可能有多个父结点,从而支持对多对一和多对多的关系进行建模。
在网络模型中,记录之间的链接不是外键,而更像是编程语言中的指针(会存储在磁盘上),访问记录的唯一方法是选择一条始于根记录的路径,并沿着相关链接依次访问。这条链接链条也因此被称为访问路径。
网络模型中的查询通过遍历记录列表,并沿着访问路径在数据库中移动游标来执行。如果记录有多个父结点,应用程序代码必须跟踪所有关系。因此其最大的问题在于它们使查询和更新数据库变得异常复杂而没有灵活性。
关系模型
关系模型所做的则是定义了所有数据的格式:关系(表)只是元组(行)集合。 没有复杂的嵌套结构,也没有复杂的访问路径。可以读取表中的任何一行或者所有行,支持任意条件查询。可以指定某些列作为键并匹配这些列来读取特定行。可以在任何表中插入新行,而不必担心与其他表之间的外键关系。
在关系数据库中,查询优化器自动决定以何种顺序执行查询,以及使用哪些索引。这些选择实际上等价于访问路径 但最大的区别在于它是由查询优化器自动生成的,而不是由应用开发人员所维护,因此不用过多地考虑它。
数据查询语言
声明式/命令式查询语言
数据查询语言通常分为以下两类:命令式查询语言、声明式查询语言。
- 命令式查询语言:其会告诉计算机以特定顺序执行某些操作。 因此我们完全可以推理整个过程,逐行遍历代码、评估相关条件、更新对应的变量,并决定是否再循环一遍。
- 声明式查询语言:只需指定所需的数据模式,结果需满足什么条件,以及如何转换数据(例如,排序、分组和聚合),而不需指明如何实现这些目标。 数据库系统的查询优化器会决定采用哪些索引和联结,以及用何种顺序来执行查询的各个语句。
声明式查询语言很有吸引力,它比命令式 API 更加简洁和容易使用。但更重要的是,它对外隐藏了数据库引擎的很多实现细节,这样数据库系统能够在不改变查询语句的情况下提高性能。
声明式语言通常适合于并行执行。 现在 CPU 提升速度的方式是增加核心数,而不是实现比之前更高的时钟频率。而命令式代码由于指定了特定的执行顺序,很难在多核和多台机器上并行。声明式语言则对于并行执行更加友好,它们仅指定了结果所满足的模式,而不指定如何得到结果的具体算法。
MapReduce查询
MapReduce 是一种编程模型,用于在许多机器上批量处理海量数据,兴起于 Google。一些 NoSQL 存储系统(包括 MongoDB 和 CouchDB)支持有限的 MapReduce 方式在大量文档上执行只读查询。
MapReduce 既不是声明式查询语言,也不是一个完全命令式的查询 API,而是介于两者之间:查询的逻辑用代码片段来表示,这些代码片段可以被处理框架重复地调用。它主要基于许多函数式编程语言中的 map 和 reduce 函数。
假设你是一名海洋生物学家,每当你看到海洋中的动物时,你都会在数据库中添加一条观察记录。现在你想生成一个报告,说明你每月看到多少鲨鱼
如果使用 SQL 来表示,代码如下:
|
|
而如果使用 MongoDB 的 MapReduce 功能,则可以按如下来表述:
|
|
MapReduce 函数对于可执行的操作有所限制。它必须是纯函数,这意味着只能使用传递进去的数据作为输入,而不能执行额外的数据库查询,也不能有任何副作用。这些限制使得数据库能够在任何位置、以任意顺序来运行函数,并在失败时重新运行这些函数。
图状数据模型
图由两种对象组成:顶点(也称为结点或实体)和边(也称为关系或弧)。很多数据可以建模为图。典型的例子包括:
- 社交网络:顶点是人,边指示哪些人彼此认识。
- Web 图:顶点是网页,边表示与其他页面的 HTML 链接。
- 公路或铁路网:顶点是交叉路口,边表示他们之间的公路或铁路线。
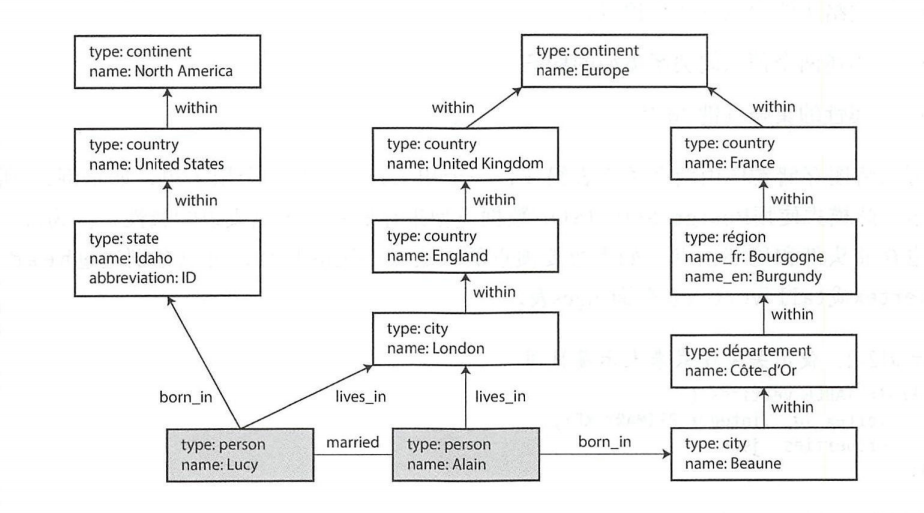
如下图,即使用图来存储族谱信息:
属性图
在属性图模型中,每个顶点包括:
-
唯一的标识符。
-
出边的集合。
-
入边的集合。
-
属性的集合(键值对) 。
每个边包括:
-
唯一的标识符。
-
边开始的顶点(尾部顶点) 。
-
边结束的顶点(头部顶点) 。
-
描述两个顶点间关系类型的标签。
-
属性的集合(键-值对)。
**可以将图存储看作由两个关系表组成,一个用于顶点, 另一个用于边。**如下列代码使用关系模式来标识属性图:
|
|
对于图模型还有一些值得注意的地方:
- 任何顶点都可以连接到其他任何顶点。没有模式限制哪种事物可以或不可以关联。
- 给定某个顶点,可以高效地得到它的所有人边和出边,从而遍历图,即沿着这些顶点链条一直向前或向后。
- 通过对不同类型的关系使用不同的标签,可以在单个图中存储多种不同类型的信息,同时仍然保持整洁的数据模型。
Cypher查询语言
Cypher 是一种用于属性图的声明式查询语言,最早为 Neo4j 图形数据库而创建。
来看看一个创建的代码示例,每个顶点都有一个像 USA、Idaho 这样的名称,查询可以使用这些名称创建顶点之间的边,如使用箭头符号: (Idaho) -[:WITHIN]-> (USA) 创建一个标签为 WITHIN 边,其中 Idaho 为尾结点, USA 为头结点。
|
|
接下来看一个使用 MATCH 语句的查询示例(查询从美国移民到欧洲的人员名单),其使用与上面相同的箭头语义:(person) -[:BORN_IN]-> () 即匹配所有顶点间带有标签 BORN_IN 的边,且尾部顶点对应于变量 person ,而头部顶点则没有要求。
|
|
该代码会匹配所有满足以下两个条件的任何顶点:
-
person有一个到其他顶点的出边BORN_IN。从该顶点开始,可以沿着一系列出边WITHIN,直到最终到达类型为Location的顶点,name属性为United StatesStates
-
person顶点也有一个出边LIVES_IN。沿着这条边,然后是一系列出边WITHIN,最终到达类型为Location的顶点,name属性为Europe。
我们不需要关注它底层是如何进行查询的,对于声明式查询语言,通常在编写查询语句时,不需要指定执行细节,查询优化器会自动选择效率最高的执行策略,因此开发者可以专注于应用的其他部分。
SQL中的图查询
既然可以使用关系数据库来表示图数据,那如果把图数据放在关系结构中,是否意味着也可以支持 SQL 查询呢?
在关系数据库中,通常会预先知道查询中需要哪些 join 操作。而对于图查询,在找到要查询的顶点之前,可能需要遍历数量未知的边。也就是说,join 操作数量并不是预先确定的。
在 SQL 查询过程中,这种可变的遍历路径可以使用递归公用表表达式(WITH RECURSIVE 语法)来表示。
例如在上面 Cypher 中提到的用例,用 SQL 表示如下:
|
|
下面来看看上述代码的逻辑:
-
首先,查找
name属性为United States的顶点,将其作为in_usa顶点的集合的第一个元素。 -
从
in_usa集合的顶点出发,沿着所有的with_in入边,将其尾顶点加入同一集合,不断递归直到所有with_in入边都被访问完毕。 -
同理,从
name属性为Europe的顶点出发,建立in_europe顶点的集合。 -
对于
in_usa集合中的每个顶点,根据born_in入边来查找出生在美国某个地方的人。 -
同样,对于
in_europe集合中的每个顶点,根据lives_in入边来查找居住在欧洲的人。 -
最后,把在美国出生的人的集合与在欧洲居住的人的集合相交。
经过对比,如果相同的查询可以用 Cypher 查询语言写 4 行代码就可以完成,而使用 SQL 需要 29 行代码,这足以说明不同的数据模型适用于不同的场景。
三元存储与SPARQL
三元存储模式几乎等同于属性图模型,只是使用不同的名词描述了相同的思想。在三元存储中,所有信息都以非常简单的三部分形式存储**(主体,谓语,客体)** 。
三元组的主体相当于图中的顶点。而客体是以下两种之一:
- 原始数据类型中的值,如字符串或数字。 在这种情况下,三元组的谓语和客体分别相当于主体(顶点)属性中的键和值。
- 图中的另一个顶点。 此时,谓语是图中的边,主体是尾部顶点,而客体是头部顶点。
我们再次拿出 Cypher 中提到的例子,以 Turtle 三元组方式来表示这些数据:
|
|
顶点的名字在定义文件以外没有任何意义,只是为了区分三元组的不同顶点。
如果要定义相同主体的多个三元组,反复输入相同的单词就略显枯燥。可以使用分号来说明同一主体的多个对象信息。下面即用更简洁的语法来重写上面的逻辑:
|
|
RDF数据模型
语义网从本质上讲源于一个简单而合理的想法:网站通常将信息以文字和图片的方式发布给人类阅读,那为什么不把信息发布为机器可读的格式给计算机阅读呢?
资源描述框架(Resource Description Framework, RDF) 就是这样一种机制,它让不同网站以一致的格式发布数据,这样来自不同网站的数据自动合并成一个数据网络,一种互联网级别包含所有数据的数据库。
Turtle 语言代表了 RDF 数据的人类可读格式。有时候 RDF 也用 XML 格式编写,不过更冗长一些,人眼容易阅读 Turtle 这种格式,因此通常会借助一些自动化工具(如 Apache Jena)来快速转换各种 RDF 格式。
下面即用 RDF/XML 语法重写上面的示例:
|
|
因为旨在为全网数据交换而设计,RDF 存在一些特殊的约定:三元组的主体、谓语和客体通常是 URI。这种设计背后的原因是其假设你的数据需要和其他人的数据相结合,万一不同的人给同一个单词附加了不同的含义,采用 URI 则可以避免冲突。
SPARQL查询语言
SPARQL 是一种采用 RDF 数据模型的三元存储查询语言,它比 Cypher 更早,并且由于 Cypher 的模式匹配是借用 SPARQL 的,所以二者看起来非常相似。
让我们再次使用 Cypher 中的那个示例,如果用 SPARQL 执行相同的查询,其会比 Cypher 要简洁的多,代码如下:
|
|
SPARQL 是一种非常优秀的查询语言, 即使语义网从未实际出现,它也可以成为应用程序内部使用的强大查询工具。
Datalog
Datalog 是比 SPARQL 和 Cypher 更为古老的语言,在 20 世纪 80 年代被学者广泛研究。其数据模型类似于三元组模式,但进行了一点泛化。把三元组写成谓语(主语,客体),而不是**(主语,谓语,客体)**。
我们尝试用 Datalog 来表示之前的查询,代码如下:
|
|
从上面的代码可以看出,Cypher 和 SPARQL 使用 SELECT 一次完成查询,而 Datalog 则每次查询一部分。我们定义了告诉数据库关于新谓语的规则。例如两个新的谓语,within_recursive 和 migrated。
这些谓语并不是存储在数据库中的三元组,而是从数据或其他规则派生而来。规则可以引用其他规则,就像函数可以调用其他函数或者递归调用自己一样。像这样,复杂的查询可以通过每次完成一小块而逐步构建。