本地文件系统
关键技术
虚拟文件系统
虚拟文件系统(Virtual File System,VFS) 是具体文件系统(如 Ext2、Ext4 和 XFS 等)与应用程序之间的一个接口层,它对 Linux 的每个文件系统的所有细节进行抽象,使得不同的文件系统在 Linux 核心以及系统中运行的其他进程看来都是相同的。以此达到使操作系统能够适配多种文件系统的目的。
VFS 提供了一个文件系统框架,本地文件系统可以基于 VFS 实现,其主要做了如下几方面的工作:
- 作为抽象层为应用层提供了统一的接口(
read、write和chmod等)。 - 实现了一些公共的功能,如 Inode 缓存(Inode Cache)和页缓存(Page Cache)等。
- 规范了具体文件系统应该实现的接口。
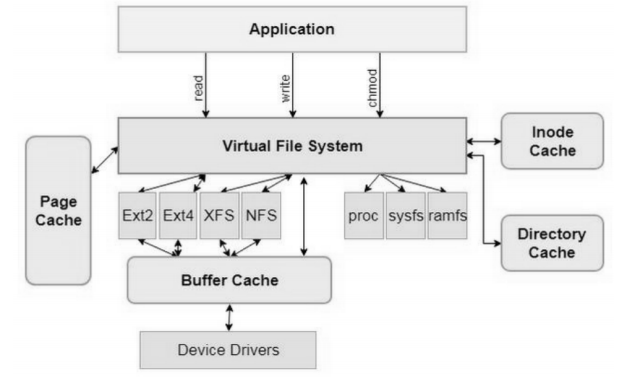
基于上述设定,其他具体的文件系统只需要按照 VFS 的约定实现相应的接口及内部逻辑,并注册在系统中,就可以完成文件系统的功能了。当用户调用操作系统提供的文件系统 API 时,会通过软中断的方式调用内核 VFS 实现的函数。
磁盘空间布局
文件系统的核心功能是实现对磁盘空间的管理。对磁盘空间的管理是指要知道哪些空间被使用了,哪些空间没有被使用。这样,在用户层需要使用磁盘空间时,文件系统就可以从未使用的区域分配磁盘空间。
为了对磁盘空间进行管理,文件系统往往将磁盘空间通常被划分为元数据区与数据区两个区域。数据区就是存储数据的地方,用户在文件中的数据都会存储在该区域;而元数据区则是对数据区进行管理的地方。
基于固定功能区的磁盘空间布局
基于固定功能区的磁盘空间布局是指将磁盘的空间按照功能划分为不同的子空间,每种子空间有具体的功能。 以 Linux 中的 Ext 文件系统为例,其空间被划分为数据区和元数据区,而元数据区又被划分为数据块位图、inode 位图和 inode 表等区域。如下图:
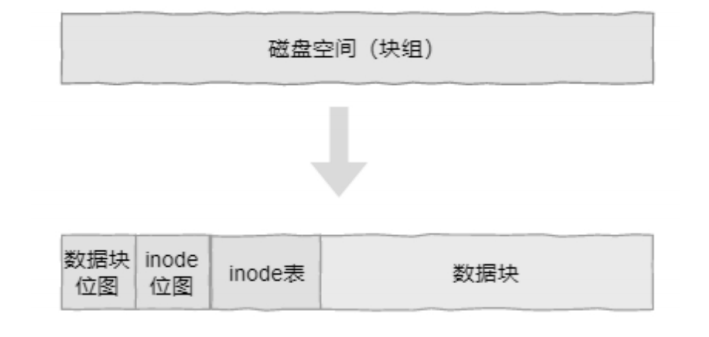
基于功能分区的磁盘空间布局空间职能清晰,便于手动进行丢失数据的恢复。但是由于元数据功能区大小固定,因此容易出现资源不足的情况==(位图长度有限)==。比如,在海量小文件的应用场景下,有可能会出现磁盘剩余空间充足,但 inode 不够用的情况
基于非固定功能区的磁盘空间布局
在磁盘空间管理中有一种非固定功能区的磁盘空间管理方法。这种方法也分为元数据和数据,但是元数据和数据的区域并非固定的,而是随着文件系统对资源的需求而动态分配的。
例如比较经典的实现 XFS,其它不是通过固定的位图区域来管理磁盘空间的,而是通过 B+ 树管理磁盘空间。这样做就可以动态的去分配元数据空间,而不是像位图一样具有限制。但是这也带来了新的问题,就是 B+ 树无法根据 inode 的偏移量来确定编号,因此 XFS 又引入复杂的编号机制来解决这个问题。
基于数据追加的磁盘空间布局
前文介绍的磁盘空间布局方式对于数据的变化都是原地修改的,也就是对于已经分配的逻辑块,当对应的文件数据改动时都是在该逻辑块进行修改的。在文件随机 I/O 比较多的情况下,不太适合使用 SSD 设备,这主要由 SSD 设备的修改和擦写特性所决定。
有一种基于数据追加的磁盘空间布局方式,也被称为基于日志(Log structured)的磁盘空间布局方式。这种磁盘空间布局方式对数据的变更并非在原地修改,而是以追加写的方式写到后面的剩余空间。这样,所有的随机写都转化为顺序写,非常适合用于 SSD 设备。
文件数据管理
对于文件系统来说,无论文件是什么格式,存储的是什么内容,它都不关心。文件就是一个线性空间,类似一个大数组。而且文件的空间被文件系统划分为与文件系统块一样大小的若干个逻辑块。文件系统要做的事情就是将文件的逻辑块与磁盘的物理块建立关系。这样当应用访问文件的数据时,文件系统可以找到具体的位置,进行相应的操作。
基于连续区域的文件数据管理
基于连续区域的文件数据管理方式是一次性为文件分配其所需要的空间,且空间在磁盘上是连续的。 由于文件数据在磁盘上是连续存储的,因此只要知道文件的起始位置所对应的磁盘位置和文件的长度就可以知道文件数据在磁盘上是如何存储的。如下图:
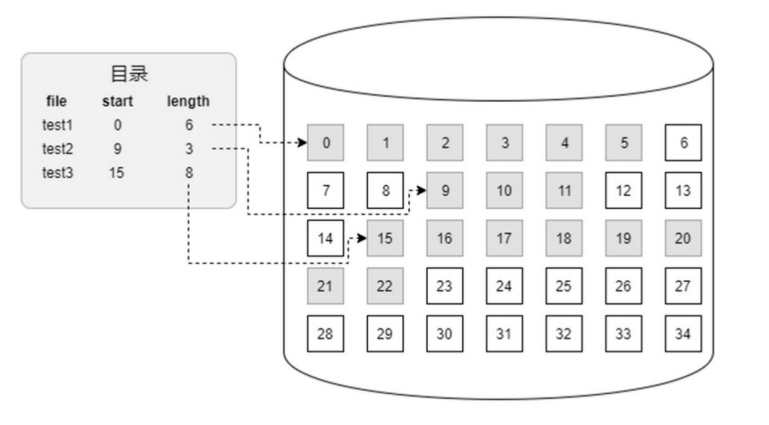
这种文件数据管理方式的最大缺点是不够灵活,特别是对文件进行追加写操作非常困难。如果该文件后面没有剩余磁盘空间,那么需要先将该文件移动到新的位置,然后才能追加写操作。如果整个磁盘的可用空间没有能够满足要求的空间,那么会导致写入失败。
除了追加写操作不够灵活,该文件数据管理方式还有另一个缺点就是容易形成碎片空间。由于文件需要占用连续的空间,因此很多小的可用空间就可能无法被使用,从而降低磁盘空间利用率。
基于链表的文件数据管理
基于链表的文件数据管理方式将磁盘空间划分为大小相等的逻辑块。 在目录项中包含文件名、数据的起始位置和终止位置。在每个数据块的后面用一个指针来指向下一个数据块。如下图:
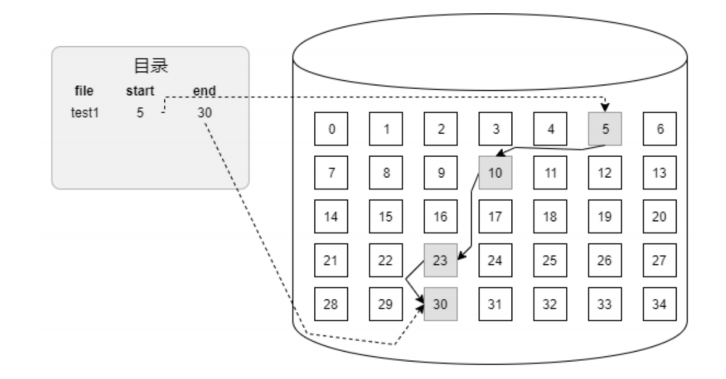
这种方式可以有效地解决连续区域的碎片问题,但是对文件的随机读/写却无能为力。这主要是因为在文件的元数据中没有足够的信息描述每块数据的位置。为了实现随机读写,还需要在实现时附加一些额外的机制。
基于索引的文件数据管理
索引方式的数据管理是指通过索引项来实现对文件内数据的管理。 如下图所示,与文件名称对应的是索引块在磁盘的位置,索引块中存储的并非用户数据,而是索引列表。当读/写数据时,根据文件名可以找到索引块的位置,然后根据索引块中记录的索引项可以找到数据块的位置,并访问数据。
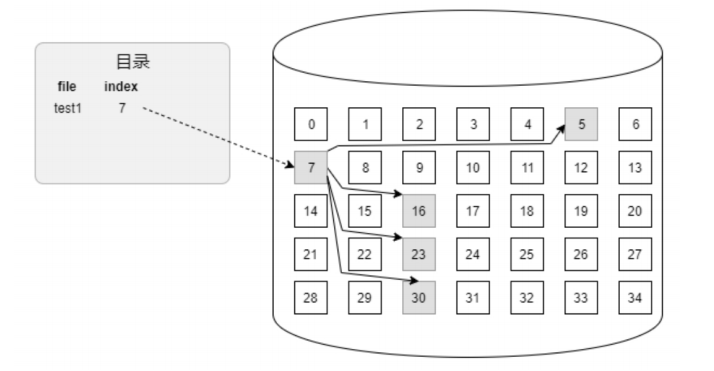
常见的索引方式有以下两种:
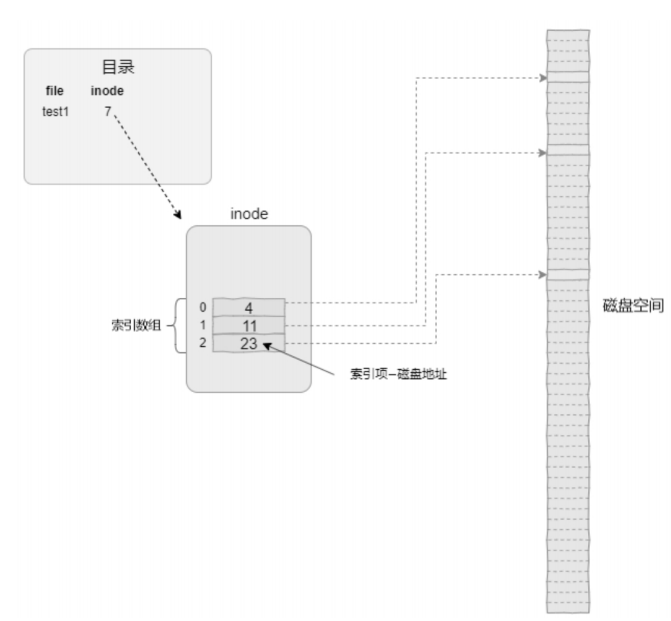
- 基于间接块的文件数据管理:在索引方式中,最为直观、简单的就是对文件的每个逻辑块都有一个对应的索引项,并将索引项用一个数组进行管理。当想要访问文件某个位置的数据时,就可以根据该文件逻辑偏移计算出数组的索引值,然后根据数组的索引值找到索引项,进而找到磁盘上的数据。
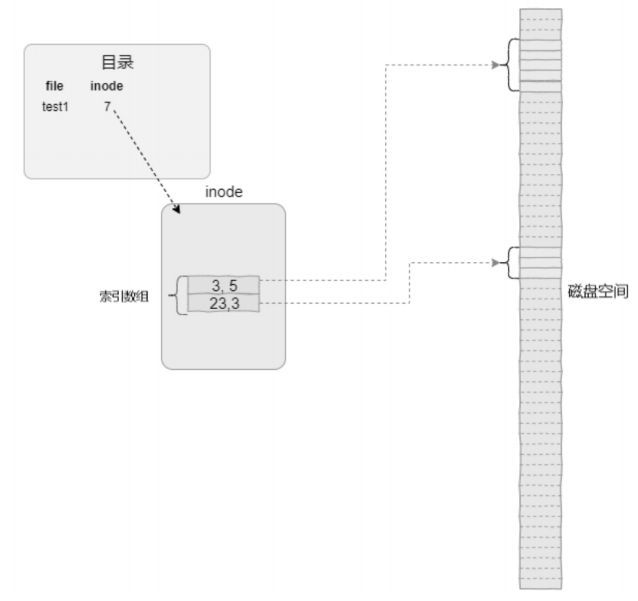
-
基于 Extent 的文件数据管理:在 Extent 文件数据管理方式中,每一个索引项记录的值不是一个数据块的地址,而是数据块的起始地址和长度。
缓存
文件系统的缓存(Cache)的作用主要用来解决磁盘访问速度慢的问题。缓存技术是指在内存中存储文件系统的部分数据和元数据而提升文件系统性能的技术。由于内存的访问延时是机械硬盘访问延时的十万分之一,因此采用缓存技术可以大幅提升文件系统的性能。
文件系统缓存的原理主要还是基于数据访问的时间局部性和空间局部性特性。时间局部性就是如果一块数据之前被访问过,那么最近很有可能会被再次访问。空间局部性则是指在访问某一个区域之后,通常会访问临近的区域。
缓存置换算法
由于内存的容量要比磁盘的容量小得多,当用户持续写入数据时就会面临缓存不足的情况,此时就涉及如何将缓存数据刷写到磁盘,然后存储新数据的问题。而将缓存数据落盘,并置换新数据的这一过程被称为缓存置换。
在文件系统中通常会采取以下这些缓存置换算法:
- LRU(Least Recently Used):LRU 基于时间局部性原理。将最久没有使用的数据淘汰出缓存。因此,当空间满时,最久没有使用的数据即被淘汰。
- LFU(Least Frequently Used):LFU 基于缓存命中频次作为置换依据。如果一个数据在最近一段时间很少被访问到,那么可以认为在将来它被访问的可能性也很小。因此,当空间满时,将命中频次最少的数据淘汰掉。
预读算法
预读算法是针对读数据的一种缓存算法。预读算法通过识别 I/O 模式方式来提前将数据从磁盘读到缓存中。这样,应用读取数据时就可以直接从缓存读取数据,从而极大地提高读数据的性能。
通常有两种情况会触发预读操作:
- 当有多个地址连续地读请求时会触发预读操作。
- 应用访问到有预读标记的缓存时会触发预读操作。这里,预读标记的缓存是在预读操作完成时在缓存页做的标记,当应用读到有该标记的缓存时会触发下一次的预读,从而省略对 I/O 模式的识别。
快照与克隆
快照(Snapshot)和克隆(Clone)技术可以应用于整个文件系统或单个文件。快照技术可以实现文件的可读备份,而克隆技术则可以实现文件的可写备份。针对文件,用的更多的是克隆技术。
快照
目前快照技术有两种实现方式:
- 写时拷贝(Copy-On-Write,COW):刚开始创建快照时原始文件和快照文件指向相同的存储区域。当原始文件被修改时,就需要将该位置的原始数据拷贝到新的位置,并且更新快照文件中的地址信息。
- 写时重定向(Redirect-On-Write,ROW):当原始文件写数据时并不在原始位置写入数据,而是分配一个新的位置写入。在读取时,创建快照前的数据从源卷读,创建快照后产生的数据,从快照卷读。
可以看出 COW 在写入时需要拷贝一份数据到快照卷的动作,而 ROW 是直接重定向到快照卷写入,所以 ROW 适合写密集型;相反,由于 ROW 不断进行指针重定向,读性能会有较大影响,而 COW 不会,所以 COW 适合读密集型。对文件系统而言,用得最多的是 ROW 方式。
克隆
克隆技术的原理与快照技术的原理类似,其相同点在于其实现方式依然是 ROW 或 COW,而差异点则主要表现在两个方面:一个方面,克隆生成的克隆文件是可以写的;另一个方面,克隆的数据最终会与原始文件的数据完全隔离。
日志
在文件系统中,一个简单的写操作在底层可能会分解为多个步骤的修改。如果不能保证操作的原子性,那么倘若出现宕机、断电的情况,此时就会导致数据的丢失、不一致,甚至是文件系统的不可用。为了解决这个问题,在文件系统中引入了日志机制。
日志通常是一块独立的空间,其采用环形缓冲区的结构,当进行文件修改操作时,相关数据块会被打包成一组操作写入日志空间,再更新实际数据。这里的一组操作被称为一个事务。
由于实际数据的更新在写入日志之后,如果在数据更新过程中出现了系统崩溃,那么通过读取日志来更新。这样就能保证数据是我们所期望的数据。还有一种异常场景是日志数据刷写过程中。由于此时日志完成标记还没有置位,而且实际数据还没有更新,那么只需要放弃该条日志即可。
权限管理
在多用户操作系统中,由于多个用户的存在,就必须实现用户之间资源访问的隔离。这种管理用户可访问资源的特性就是权限管理。
RWX 权限管理
Linux最常用的权限管理就是 RWX-UGO 权限管理。其中,RWX 是 Read、Write 和 eXecute 的缩写。而 UGO 则是 User、Group 和 Other 的缩写。通过该机制建立用户和组实现对文件的不同的访问权限。
如下图所示:
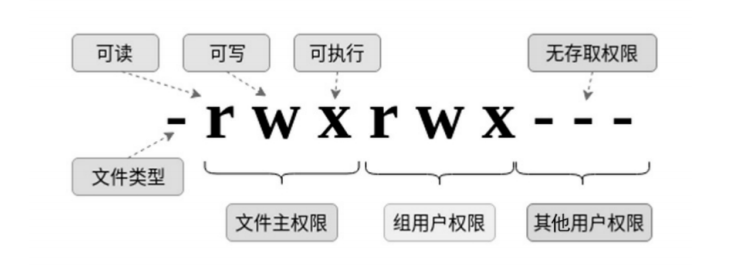
当我们对文件进行操作时,首先会调用 inode_permission() 函数来判断执行用户的访问权限,如果权限不足则阻止对应操作的执行。
ACL 权限管理
ACL(Access Control List,访问控制列表),是一个针对文件/目录的访问控制列表。它在 RWX-UGO 权限管理的基础上为文件系统提供一个额外的、更灵活的权限管理机制。ACL 允许给任何用户或用户组设置任何文件/目录的访问权限,这样就能形成网状的交叉访问关系。
根据是否继承父目录的 ACL 属性,ACL 分为以下两类:
- access ACL:每一个对象(文件/目录)都可以关联一个 ACL 来控制其访问权限,这样的 ACL 被称为 access ACL。
- default ACL:目录关联的一种 ACL。当目录具备该属性时,在该目录中创建的对象(文件或子目录)默认具有相同的 ACL。
ACL 在操作系统内部是通过文件的扩展属性实现的。 当用户为文件添加一个 ACL 规则时,其实就是为该文件添加一个扩展属性。如下图:
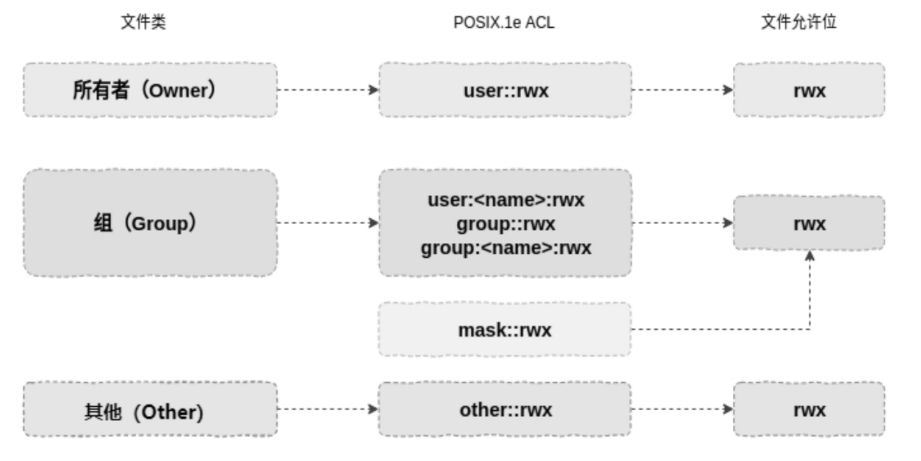
需要注意的是,ACL 的数据与文件的普通扩展属性数据存储在相同的位置,只不过通过特殊的标记进行了区分,这样就可以屏蔽普通用户对 ACL 的访问。
SELinux 权限管理
SELinux(Security-Enhanced Linux)是一个在内核中实现的强制存取控制(MAC)安全性机制。SELinux 与 RWX、ACL 最大的区别是基于访问者(应用程序)与资源的规则,而不是用户与资源的规则,因此其安全性更高。这里基于应用程序与资源的规则是指规定了哪些应用程序可以访问哪些资源,而与运行该应用程序的用户无关。
SELinux 通过将权限从用户收缩到应用,即使应用被攻破,黑客也只能访问应用程序所限定的资源,而不会扩散到其他地方。
其原理图如下:
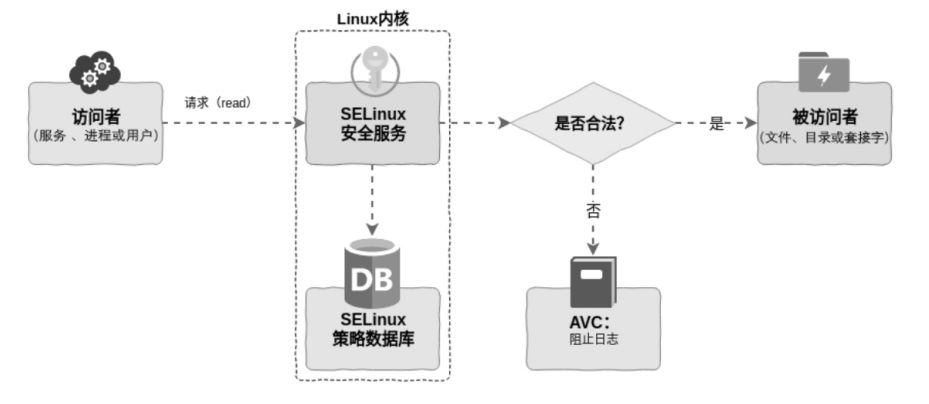
当访问者访问被访问者(资源)时,需要调用内核的接口,此时会经过 SELinux 内核的判断逻辑,该判断逻辑根据策略数据库的内容确定访问者是否有权访问被访问者,如果允许访问则放行,否则拒绝该请求并记录审计日志
配额管理
在多用户环境中,不仅要防止用户对其他用户数据的非法访问,还要确保某些用户所使用的存储空间不能太多。在这种情况下,就需要一种配额 (Quota)管理技术。
配额管理是一种对使用空间进行限制的技术,其主要包括针对用户(或组)的限制和针对目录的限制两种方式。针对用户(或组)的限制是指某一个用户(或组)对该文件系统的空间使用不能超过设置的上限,如果超过上限则无法写入新的数据。针对目录的限制是指该目录中的内容总量不能超过设置的上限。
在配额管理中,通常涉及三个基本概念:
- 软上限(Soft Limit):指数据总量可以超过该上限。如果超过该上限则会有一个告警信息。
- 硬上限(Hard Limit):指数据总量不可以超过该上限,如果超过该上限则无法写入新的数据。
- 宽限期(Grace Period):宽限期通常是针对软上限而言的。如果设置了该值(如 3 天),则在 3 天内允许数据量超过软上限,当超过3天后,无法写入新的数据。
其实现的原理非常简单,当有新的写入请求时,配额模块就会去分析该请求。如果需要计入配额管理中,则进行配额上限的检查,在小于上限的情况下会更新配额管理数据,否则将阻止新的数据写入,并发出告警信息。
文件锁
文件锁的基本作用就是保证多个进程对某个文件并发访问时数据的一致性。如果没有文件锁,就有可能出现多个进程同时访问文件相同位置数据的问题,从而导致文件数据的不一致性。
文件锁分为以下两种类型:
- 劝告锁(Advisory Lock):劝告锁是一种建议性的锁,通过该锁告诉访问者现在该文件被其他进程访问,但不强制阻止访问。
- 强制锁(Mandatory Lock):强制锁则是在有进程对文件锁定的情况下,其他进程是无法访问该文件的。
为了提高性能,减少等待锁时间,以上两种锁都引入了共享锁、排他锁机制。
- 共享锁(Shared Lock):在任意时间内,一个文件的共享锁可以被多个进程拥有,共享锁不会导致系统进程的阻塞。
- 排他锁(Exclusive Lock):在任意时间内,一个文件的排他锁只能被一个进程拥有。
当有新的加锁请求到来时,其会与已有的锁信息逐一比对,判断是否存在锁冲突。如果存在,则将该进程置为休眠状态(阻塞,如果为非阻塞则返回直接错误码)。如果不存在,则将锁信息记录下来后允许用户访问。