智能指针
条款 18:使用 std::unique_ptr 管理具备专属所有权的资源
-
std::unique_ptr 是轻量级、高速、只能 move 的智能指针,对托管资源实施专属所有权语义(通过 delete 拷贝操作实现)。
-
默认情况下,资源销毁采用 delete 来实现,但我们也可以自定义删除器。有状态的删除器和函数指针会增加 std::unique_ptr 的大小(函数指针的大小 + 状态的大小)。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18auto delInvmt1 = [](Investment* pInvestment) //无状态lambda的 { //自定义删除器 makeLogEntry(pInvestment); delete pInvestment; }; template<typename... Ts> //返回类型大小是 std::unique_ptr<Investment, decltype(delInvmt1)> //Investment*的大小 makeInvestment(Ts&&... args); void delInvmt2(Investment* pInvestment) //函数形式的 { //自定义删除器 makeLogEntry(pInvestment); delete pInvestment; } template<typename... Ts> //返回类型大小是 std::unique_ptr<Investment, void (*)(Investment*)> //Investment*的指针 makeInvestment(Ts&&... params); //加至少一个函数指针的大小
-
-
很容易就可以将 std::unique 转化为 std::shared_ptr。
-
1 2 3 4 5std::shared_ptr<std::string> str_sp2 = std::unique_ptr<std::string>(new std::string("TEST"))) //如果要以已经存在的unique_ptr,则需要move std::unique_ptr<std::string> str_up = std::make_unique<std::string>("TEST"); std::shared_ptr<std::string> str_sp = std::move(str_up);
-
条款 19:使用 std::shared_ptr 管理具备共享所有权的资源
-
std::shared_ptr 实现了任意资源在共享所有权语义下进行生命周期管理的垃圾回收(通过引用计数实现)。
-
与 std::unique_ptr 相比,std::shared_ptr 的大小通常是裸指针的两倍,且还会带来控制块的开销,并要求使用原子化的引用计数操作。
- 引用计数的内存必须要动态分配,并且原子计数会消耗大量 CPU 资源。
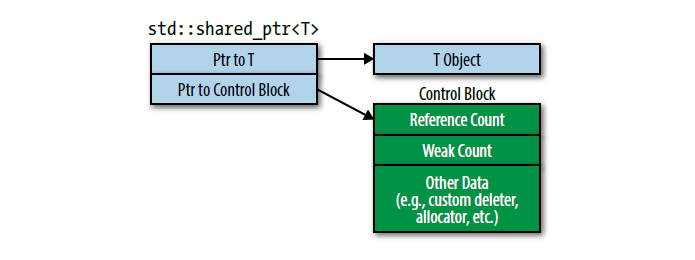
- std::shared_ptr 的大小是裸指针的两倍,成员中包含了一个指向数据块的指针与一个指向控制块的指针。同时控制块中包含了引用计数、weak 计数、其他数据(例如分配器、自定义删除)。
-
默认的资源析构通过 delete 进行,但也支持自定义删除器。删除器的类型对 std::shared_ptr 的类型没有影响。
-
对于std::unique_ptr来说,删除器类型是智能指针类型的一部分。而对于std::shared_ptr 则不是,其将删除器作为成员的一部分,将其拷贝后保存至控制块中。由于删除器保存控制块中,如果删除器过大,则会浪费内存。
1 2 3 4 5 6 7auto customDeleter1 = [](Widget *pw) { … }; //自定义删除器, auto customDeleter2 = [](Widget *pw) { … }; //每种类型不同 std::shared_ptr<Widget> pw1(new Widget, customDeleter1); std::shared_ptr<Widget> pw2(new Widget, customDeleter2); //删除器对类型没有影响,因此它们类型相同,可以放到同一个容器中,也可以互相给对方赋值。 std::vector<std::shared_ptr<Widget>> vpw{ pw1, pw2 };
-
-
避免使用裸指针类型的变量来创建 std::shared_ptr。
-
如果用一个裸指针来创建多个 std::shared_ptr,则会导致多个控制块的建立,并进行多重的引用计数。这不仅仅只是空间的浪费,还会导致同一个对象被多次析构,导致程序报错。
1 2 3 4 5auto pw = new Widget; //pw是原始指针 … std::shared_ptr<Widget> spw1(pw, loggingDel); //为*pw创建控制块 … std::shared_ptr<Widget> spw2(pw, loggingDel); //为*pw创建第二个控制块
-
条款 20:当 std::shared_ptr 可能空悬时使用 std::weak_ptr
-
当 std::shared_ptr 可能空悬时使用 std::weak_ptr。
-
由于 std::weak_ptr 并不参与 std::shared_ptr 的计数与资源管理,且它们指向的是同一块资源,因此我们可以使用 std::weak_ptr 来检测 std::shared_ptr 所指向的资源是否已销毁(当 weak_count 不为零时,控制块并不会销毁,因此可以使用 std::weak_ptr 查看资源是否析构。)。
1 2 3 4 5 6//方法一:调用成员函数expired(),但是在并发环境下可能存在问题,即在if判断未过期后,结果另一个线程却将数据析构了,此时就访问到了已删除数据。 if (wpw.expired()) … //如果wpw没有指向对象… //方法二:使用lock将weak_ptr升级为shared_ptr,或者直接用其构造出shared_ptr std::shared_ptr<Widget> spw1 = wpw.lock(); //如果wpw过期,spw1就为空 std::shared_ptr<Widget> spw3(wpw); //如果wpw过期,抛出std::bad_weak_ptr异常
-
-
std::weak_ptr 主要用于缓存、观察者模式,以及避免 std::shared_ptr 出现循环引用。
条款 21:优先使用 std::make_unique 和 std::make_shared 而非 new
-
相比于直接使用 new,make 系列函数消除了重复代码,提高了异常安全性。并且对于 std::make_shared 和 std::allcoated_shared 而言,生成的目标代码更小、更快。
-
make 系列函数消除了重复代码,避免重复撰写类型:
1 2 3 4 5 6//不使用make函数时要多写一次类型 auto upw1(std::make_unique<Widget>()); //使用make函数 std::unique_ptr<Widget> upw2(new Widget); //不使用make函数 auto spw1(std::make_shared<Widget>()); //使用make函数 std::shared_ptr<Widget> spw2(new Widget); //不使用make函数 -
make 函数提高了异常安全性:
1 2 3 4 5 6 7 8 9void processWidget(std::shared_ptr<Widget> spw, int priority); int computePriority(); processWidget(std::shared_ptr<Widget>(new Widget), //潜在的资源泄漏! computePriority()); processWidget(std::make_shared<Widget>(), //没有潜在的资源泄漏 computePriority());由于 new 和 computePriority()、构造 std::shared_ptr 的操作顺序并不确定,因此有可能先 new 资源,然后执行 computePriority(),最后再构造 std::shared_ptr。而如果 computePriority() 中出现了异常,就会导致 new 出来的资源无法被用来构造 shared_ptr,因此出现了内存泄漏的问题。而如果使用 make 函数,则将 new 和构造 std::shared_ptr 放到了一起操作,因此不会出现这样的问题。
-
-
不适合使用 make 函数的情况包括需要自定义删除器,以及使用大括号初始化。
-
make 系列函数不允许指定自定义删除器,此时只能使用 new:
1 2 3 4 5 6auto widgetDeleter = [](Widget* pw) { … }; std::unique_ptr<Widget, decltype(widgetDeleter)> upw(new Widget, widgetDeleter); std::shared_ptr<Widget> spw(new Widget, widgetDeleter); -
此时又出现了条款 7 中提到的问题,但 make 系列中对形参进行完美转发的代码使用的是小括号,因此不会有不确定性。这也就导致了 make 无法使用大括号,此时只能用 new。
1 2 3//完美转发的代码使用的是(),因此vector中有10个值为20的元素 auto upv = std::make_unique<std::vector<int>>(10, 20); auto spv = std::make_shared<std::vector<int>>(10, 20);但这个问题其实还有一个另类的解决方法,即用 auto 推导出大括号初始化的类型 std::initializer_list<T>,并将这个 auto 对象传递给 make,即可间接使用大括号初始化:
1 2 3 4//创建std::initializer_list auto initList = { 10, 20 }; //使用std::initializer_list为形参的构造函数创建std::vector auto spv = std::make_shared<std::vector<int>>(initList); -
对于直接使用 new 来构造的 std::shared_ptr,其首先会分配 Widget 的内存,接着将数据块指针指向这块内存,接着再去构建控制块,此时进行了两次内存分配,且两块内存不连续,在析构时还需要析构两次。而使用 make 函数构造的 std::shared_ptr,一次性申请/释放了数据块和控制块的内存,大大提升了性能,并且两者都是连续的,还能避免内存碎片的问题。
1 2 3std::shared_ptr<Widget> spw(new Widget); //两次内存分配 auto spw = std::make_shared<Widget>(); //一次内存分配
-
-
对于 std::shared_ptr,不建议使用 make 系列函数的额外场景包括:
-
自定义内存管理的类。
- 例如自定义了 operator new 和 operator delete 的类只处理了原本数据块的内存,而并没有考虑到控制块的内存。
-
内存紧张的系统、非常大的对象,以及指向同一资源的 std::weak_ptr 比对应的 std::shared_ptr 的生命周期更长。
- 如果 std::weak_ptr 比对应的 std::shared_ptr 的生命周期更长,则控制块的内存一直无法释放,而由于 make_shared 的控制块和数据块是连续的,则这块内存也就都一直无法释放,直到 weak_count 清零。
-
条款 22:使用 PImpl 用法时,将特殊成员函数的定义放到实现文件中
-
Pimpl 惯用法通过降低类实现和类使用者之间的编译依赖,来减少编译时间。
-
这里以一个 Widget 类举例。由于 Widget 中有着 std::string、std::vector、Gadget 等类型,因此其依赖头文件 <string>、<vector>、Gadget.h。只有这些头文件存在时,它才能通过编译。这些头文件不仅增加了编译时间,还由于它们之间存在依赖关系,如果某个头文件的内容发现了变化,Widget 也需要重新编译。
1 2 3 4 5 6 7 8 9class Widget() { //定义在头文件“widget.h” public: Widget(); … private: std::string name; std::vector<double> data; Gadget g1, g2, g3; //Gadget是用户自定义的类型 };此时就可以考虑使用 Pimpl 惯用法来优化这个问题,即把类的数据成员替代为一个指向实现类(或结构体)的指针,例如下面的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29class Widget //仍然在“widget.h”中 { public: Widget(); ~Widget(); //析构函数在后面会分析 … private: struct Impl; //声明一个 实现结构体 Impl *pImpl; //以及指向它的指针 }; #include "widget.h" //以下代码均在实现文件“widget.cpp”里 #include "gadget.h" #include <string> #include <vector> struct Widget::Impl { //含有之前在Widget中的数据成员的 std::string name; //Widget::Impl类型的定义 std::vector<double> data; Gadget g1,g2,g3; }; Widget::Widget() //为此Widget对象分配数据成员 : pImpl(new Impl) {} Widget::~Widget() //销毁数据成员 { delete pImpl; }此时因为 Widget 不再依赖这些类型(依赖关系从头文件转移到实现文件,用户不可见),也就不再需要这些头文件,大大的提升了编译速度。且因为摆脱了依赖关系,即使这些头文件的内容发生了改变,也不会对 Widget 造成任何影响。
-
-
对于 std::unique_ptr 类型的 pImpl 指针,需要在类的头文件中声明特殊成员函数,并在实现文件中实现它们。即使默认生成的函数可以正常工作,我们也必须这样做。
-
当我们想使用 std::unique_ptr 来管理 PImpl 指针时,通常会出现一个奇怪的问题,例如下面这个代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29class Widget { //在“widget.h”中 public: Widget(); … private: struct Impl; std::unique_ptr<Impl> pImpl; //使用智能指针而不是原始指针 }; #include "widget.h" //在“widget.cpp”中 #include "gadget.h" #include <string> #include <vector> struct Widget::Impl { //跟之前一样 std::string name; std::vector<double> data; Gadget g1,g2,g3; }; Widget::Widget() //根据条款21,通过std::make_unique : pImpl(std::make_unique<Impl>()) //来创建std::unique_ptr {} //上述代码能够通过编译(前提是没有构造Widget对象) #include "widget.h" Widget w; //错误!声明和定义 Wigdet 的代码都能够通过编译,但是只要我们创建了一个 Widget 对象,就会导致编译不通过。
当我们进行排错时,发现原因竟然是 Widget 并没有生成析构函数。为什么会这样呢?在我们的印象中,即使我们没有显式声明,编译器也会默认提供,但此时为什么没有呢?这就需要提到 unique_ptr 的内部机制了。
在介绍之前,首先我们要知道什么是不完整类型。
不完整类型指的是该类型缺乏足够的信息例如长度去描述一个完整的对象。也就是说,如果在编译期编译器能计算出一个类型的size,那么它就是一个完整类型,否则就是不完整类型。
因此声明了但是未定义的类、未知大小的数组、包含不完整成员、void类型,都属于不完整类型。
当编译器发现 Widget 中并没有显式定义构造函数时,就会开始自动生成构造函数,而在生成的过程中,就需要考虑析构掉 unique_ptr 所管理的 Impl 对象。由于我们并没有自定义删除器,因此 unique_ptr 内部会尝试调用 delete 来删除 Impl。但在删除之前,unique_ptr 会通过 static_assert 去确保管理的裸指针未涉及非完整类型,这时就会产生报错。
**为了解决这个问题,我们只需要保证在编译器生成析构函数时,Widget::Impl 是一个完整类型。**因此我们可以将这个过程后推到实现文件中——即在头文件中加上析构函数的声明,避免编译器自动生成。而在声明函数中使用 default 告诉编译器生成析构函数,由于 Widget::Impl 的定义也在定义文件中,此时它已经成为了完整类型,就不再有上面提到的这个问题。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27class Widget { //跟之前一样,在“widget.h”中 public: Widget(); ~Widget(); //只有声明语句 … private: //跟之前一样 struct Impl; std::unique_ptr<Impl> pImpl; }; #include "widget.h" //跟之前一样,在“widget.cpp”中 #include "gadget.h" #include <string> #include <vector> struct Widget::Impl { //跟之前一样,定义Widget::Impl std::string name; std::vector<double> data; Gadget g1,g2,g3; } Widget::Widget() //跟之前一样 : pImpl(std::make_unique<Impl>()) {} Widget::~Widget() = default; //析构函数的定义
-
-
上述建议仅适用于 std::unique_ptr,不适用于 std::shared_ptr。
- 对于 std::unique_ptr 而言,自定义删除器是类型的一部分,这虽然使得编译器生成了更小的运行期数据结构以及更快的运行期代码,但这带来了一个后果——如果要使用编译器生成的特殊函数,就要求指涉的类型必须是完整类型。
- 对于 std::shared_ptr 而言,自定义删除器不是类型的一部分,而是控制块的一部分。这就使得编译器生成了更大的运行期数据结构以及更慢的运行期代码,但使用编译器生成的特殊函数时,就要求指涉的类型就不要求是完整类型。