ElasticSearch 基本概念

Elasticsearch是一个分布式的免费开源搜索和分析引擎,适用于包括文本、数字、地理空间、结构化和非结构化数据等在内的所有类型的数据。
Elasticsearch在Apache Lucene的基础上开发而成。然而,Elasticsearch不仅仅是Lucene,并且也不仅仅只是一个全文搜索引擎。 它可以被下面这样准确的形容:
- 一个分布式的实时文档存储,每个字段都可以被索引与搜索
- 一个分布式实时分析搜索引擎
- 能胜任上百个服务节点的扩展,并支持PB级别的结构化或者非结构化数据
Lucene
Lucene是一套用于全文索引和搜索的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜索。但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。
Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
在Java开发环境里Lucene是一个成熟的免费开源工具。就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索程序库。人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆。
ELK
Elastic Stack是一套适用于数据采集、扩充、存储、分析和可视化的免费开源工具。人们通常将Elastic Stack称为ELK Stack(代指 Elasticsearch、Logstash 和 Kibana)。
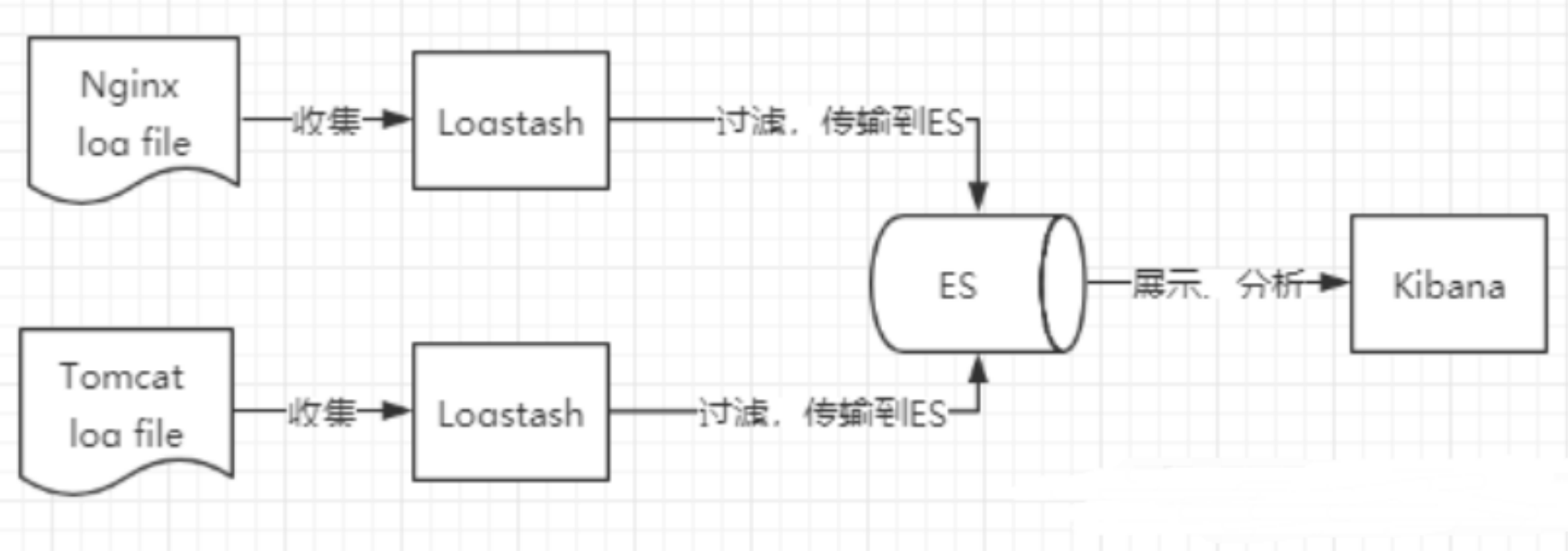
Logstash是什么?
Logstash 是 Elastic Stack 的核心产品之一,可用来对数据进行聚合和处理,并将数据发送到 Elasticsearch。Logstash 是一个开源的服务器端数据处理管道,允许您在将数据索引到 Elasticsearch 之前同时从多个来源采集数据,并对数据进行充实和转换。
Kibana是什么?
Kibana 是一款适用于Elasticsearch的数据可视化和管理工具,可以提供实时的直方图、线形图、饼状图和地图。Kibana同时还包括诸如 Canvas和Elastic Maps等高级应用程序
- Canvas允许用户基于自身数据创建定制的动态信息图表,
- Elastic Maps用来对地理空间数据进行可视化。
Elasticsearch的特点
-
Elasticsearch 很快。 由于Elasticsearch是在Lucene基础上构建而成的,所以在全文本搜索方面表现十分出色。Elasticsearch同时还是一个近实时的搜索平台,这意味着从文档索引操作到文档变为可搜索状态之间的延时很短,一般只有一秒。因此,Elasticsearch 非常适用于对时间有严苛要求的用例,例如安全分析和基础设施监测。
-
Elasticsearch 具有分布式的本质特征。 Elasticsearch中存储的文档分布在不同的容器中,这些容器称为分片,可以进行复制以提供数据冗余副本,以防发生硬件故障。Elasticsearch的分布式特性使得它可以扩展至数百台(甚至数千台)服务器,并处理 PB 量级的数据。
-
Elasticsearch 包含一系列广泛的功能。 除了速度、可扩展性和弹性等优势以外,Elasticsearch 还有大量强大的内置功能(例如数据汇总和索引生命周期管理),可以方便用户更加高效地存储和搜索数据。
-
Elastic Stack 简化了数据采集、可视化和报告过程。 通过与 Beats 和 Logstash 进行集成,用户能够在向 Elasticsearch 中索引数据之前轻松地处理数据。同时,Kibana 不仅可针对 Elasticsearch 数据提供实时可视化,同时还提供 UI 以便用户快速访问应用程序性能监测 (APM)、日志和基础设施指标等数据。
应用场景
Elasticsearch在速度和可扩展性方面都表现出色,而且还能够索引多种类型的内容,这意味着其可用于多种用例:
- 应用程序搜索
- 网站搜索
- 企业搜索
- 日志处理和分析
- 基础设施指标和容器监测
- 应用程序性能监测
- 地理空间数据分析和可视化
- 安全分析
- 业务分析
架构设计
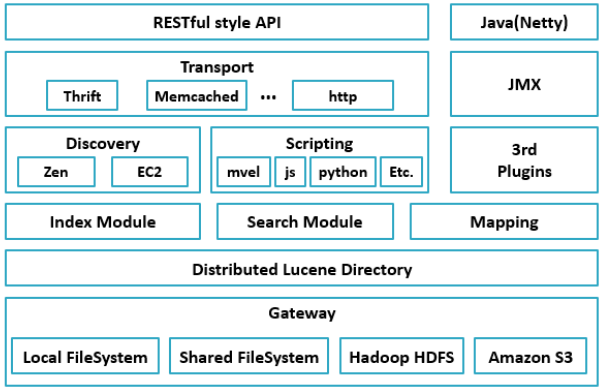
- Gateway:Elasticsearch用来存储索引的文件系统,支持多种类型。ElasticSearch默认先把索引存储在内存中,然后当内存满的时候,再持久化到Gateway里。当ES集群关闭或重启的时候,它就会从Gateway里去读取索引数据。比如LocalFileSystem和HDFS、AS3等。
- DistributedLucene Directory:Lucene里的一些列索引文件组成的目录。它负责管理这些索引文件。包括数据的读取、写入,以及索引的添加和合并等。
- Mapping:映射解析模块。
- Search Moudle:搜索模块。
- Index Moudle:索引模块。
- Disvcovery:节点发现模块。不同机器上的节点要组成集群需要进行消息通信,集群内部需要选举master节点,这些工作都是由Discovery模块完成。支持多种发现机制,如 Zen 、EC2、gce、Azure。
- Scripting:Scripting用来支持在查询语句中插入javascript、python等脚本语言。
- 3rd plugins:第三方插件。
- Transport:传输模块,支持多种传输协议,如 Thrift、memecached、http,默认使用http。
- JMX:JMX是java的管理框架,用来管理ES应用。
- Java(Netty):java的通信框架。
- RESTful Style API:提供给用户的接口,通过RESTful方式来实现API编程。
基本概念
Elasticsearch是一个文档型数据库,为了方便理解,下面给出其与传统的关系型数据库的对比
| Relational DB | Elasticsearch |
|---|---|
| 数据库 Database | 索引 Index |
| 表 Table | 类型 Type |
| 行 Rows | 文档 Document |
| 列 columns | 字段 fields |
| 表结构 schema | 映射 mapping |
文档
Elasticsearch是面向文档的,索引和搜索数据的最小单位是文档,并且使用JSON来作为文档的序列化格式。每个文档可以由一个或多个字段组成,类似于关系型数据库中的一行记录,在Elasticsearch中,文档有几个重要属性
- 自我包含:一篇文档同时包含字段和对应的值。
- 层次型:文档中还可以包含新的文档,一个字段的取值也可以包含其他字段和取值。
- 结构灵活:文档不依赖预先定义的模式。在关系型数据库中,要提前定义字段才能使用,在Elasticsearch中,对于字段是非常灵活的,有时候,我们可以忽略该字段,或者动态的添加一个新的字段。
尽管我们可以随意的新增或者忽略某个字段,但是,每个字段的类型非常重要,比如一个年龄字段类型,可以是字 串也可以是整形。因为Elasticsearch会保存字段和类型之间的映射及其他的设置。这种映射具体到每个映射的每种类型,这也是为什么在Elasticsearch中,类型有时候也称为映射类型。
类型
类型是文档的逻辑容器,类似于表格是行的容器。在不同的类型中,最好放入不同结构的文档。(有点类似于关系型数据库中的表的概念)。
每个类型中对于字段的定义称为映射。比如name字段映射为string类型。 我们说文档是无模式的,它们不需要拥有映射中所定义的所有字段,例如我们可能会新增一个映射中不存在的字段,那么Elasticsearch是怎么做的呢?
Elasticsearch会自动的将新字段加入映射,由于不确定这个字段是什么类型,Elasticsearch就会根据字段的值来推导它的类型,如果这个值是10,那么Elasticsearch会认为它是整形。 但是这种推导也可能会存在问题,如果这里的10实际上是字符串“10”,如果后续在索引字符串“hello world”,就会因为类型不一致而导致索引失败。 所以最安全的方式就是在索引数据之前,就定义好所需要的映射,这点跟关系型数据库殊途同归了,先定义好字段,然后再使用。
映射类型只是将文档进行逻辑划分。从物理角度来看,同一索引的文档都是写入磁盘,而不考虑它们所属的映射类型。
注意⚠️:为什么ElasticSearch要在7.X版本去掉type?
在Elasticsearch设计初期,是直接查考了关系型数据库的设计模式,存在了类型(表)的概念。 但是,其搜索引擎是基于Lucene的,这种基因决定了类型是多余的。Lucene的全文检索功能之所以快,是因为倒序索引的存在。 而这种倒序索引的生成是基于索引的,而并非 类型。多个类型反而会减慢搜索的速度——两个不同type下的两个user_name,在ES同一个索引下其实被认为是同一个filed,你必须在两个不同的type中定义相同的filed映射。否则,不同type中的相同字段名称就会在处理中出现冲突的情况,导致Lucene处理效率下降。
索引
在Elasticsearch中,索引有两个含义:
-
名词
- 索引是映射类型的容器,Elasticsearch中的索引是一个非常大的文档集合,非常类似关系型数据库中库的概念。索引存储了所有映射类型的字段。
-
动词
- 索引一个文档就是存储一个文档到一个索引 (名词)中以便被检索和查询。这非常类似于SQL中的
INSERT关键词,不同的是文档已存在时,新文档会替换旧文档(UPSERT)。
- 索引一个文档就是存储一个文档到一个索引 (名词)中以便被检索和查询。这非常类似于SQL中的
在Elasticsearch中,索引使用了一种称为倒排索引(即通过查询词索引到文档)的结构,它适用于快速的全文搜索。一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,有一个包含它的文档列表。