索引原理
倒排索引
例如,假设我们有两个文档,每个文档的 content 域包含如下内容:
- The quick brown fox jumped over the lazy dog
- Quick brown foxes leap over lazy dogs in summer
为了创建倒排索引,首先我们需要借助分词器,将每个文档的 content 域拆分成单独的词(我们称它为 词条 或 tokens、term ),创建一个包含所有不重复词条的排序列表,然后列出每个词条出现在哪个文档。
|
|
如果我们想搜索 quick brown ,我们只需要查找包含每个词条的文档:
|
|
这里我们匹配到了两个文档(为了节省空间,这里返回的只是文档ID,最后再通过文档id去查询到具体文档。)。对于搜索引擎来说,用户总希望能够先看到相关度更高的结果,因此实际使用时我们通过一些算法来进行权重计算,将查询的结果按照权重降序返回。
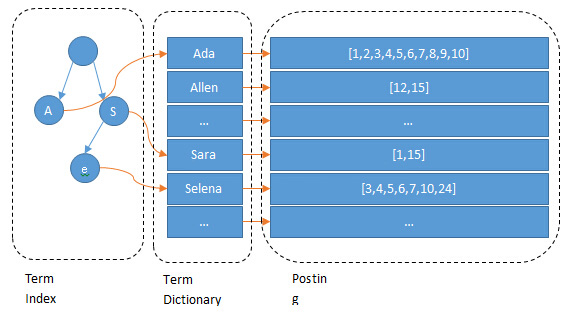
Term dictionary与Term index
Elasticsearch为了能够快速的在倒排索引中找到某个term,他会按照字典序对所有的term进行排序,再通过二分查找来找到term,这就是Term Dictionary,但即使有了Term Dictionary,O(logN)的磁盘读写仍然是影响性能的一大问题。
B-Tree通过减少磁盘寻道次数来提高查询性能,Elasticsearch也是采用同样的思路,直接通过内存查找term,不读磁盘,但是如果term太多,term dictionary也会很大,放内存不现实,于是有了Term Index,从下图可以看出,Term Index其实就是一个Trie树(前缀树)
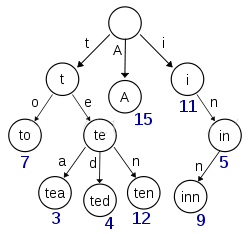
这棵树不会包含所有的term,它包含的是term的一些前缀。通过term index可以快速地定位到term dictionary的某个offset,然后从这个位置再往后顺序查找。
为什么Elasticsearch/Lucene检索比mysql快呢?
Mysql只有term dictionary这一层,是以b-tree排序的方式存储在磁盘上的。检索一个term需要若干次的random access的磁盘操作。而Lucene在term dictionary的基础上添加了term index来加速检索,term index以树的形式缓存在内存中。从term index查到对应的term dictionary的block位置之后,再去磁盘上找term,大大减少了磁盘的random access次数。
列式存储——Doc Values
Doc values的存在是因为倒排索引只对某些操作是高效的。 倒排索引的优势在于查找包含某个项的文档,而对于从另外一个方向的相反操作并不高效,即:确定哪些项是否存在单个文档里,聚合需要这种次级的访问模式。
以排序来举例——虽然倒排索引的检索性能非常快,但是在字段值排序时却不是理想的结构。
- 在搜索的时候,我们能通过搜索关键词快速得到结果集。
- 当排序的时候,我们需要倒排索引里面某个字段值的集合。换句话说,我们需要
转置倒排索引。
转置 结构经常被称作 列式存储 。它将所有单字段的值存储在单数据列中,这使得对其进行操作是十分高效的,例如排序、聚合等操作。
在Elasticsearch中,Doc Values就是一种列式存储结构,在索引时与倒排索引同时生成。也就是说Doc Values和倒排索引一样,基于 Segement生成并且是不可变的。同时Doc Values和倒排索引一样序列化到磁盘。
Doc Values常被应用到以下场景:
- 对一个字段进行排序
- 对一个字段进行聚合
- 某些过滤,比如地理位置过滤
- 某些与字段相关的脚本计算
下面举一个例子,来讲讲它是如何运作的
假设存在以下倒排索引
1 2 3 4 5 6Term Doc_1 Doc_2 Doc_3 ------------------------------------ brown | X | X | dog | X | | X dogs | | X | X ------------------------------------那么其生成的DocValues如下(实际存储时不会存储doc_id,值所在的顺位即为doc_id)
1 2 3 4 5 6 7 8 9Doc_id Values ------------------ Doc_1 | brown | Doc_1 | dog | Doc_2 | brown | Doc_2 | dogs | Doc_3 | dog | Doc_3 | dogs | ------------------假设我们需要计算出brown出现的次数
|
|
下面来分析上述请求在ES中是如何来进行查询的:
- 定位数据范围。通过倒排索引,来找到所有包含brown的doc_id。
- 进行聚合计算。借助doc_id在doc_values中定位到为brown的字段,此时进行聚合累加得到计算结果。browm的count=2。
但是doc_values仍存在一些问题,其不支持analyzed类型的字段,因为这些字段在进行文本分析时可能会被分词处理,从而导致doc_values将其存储为多行记录。但是在我们实际使用时,为什么仍然能对analyzed的字段进行聚合操作呢?这时就需要介绍一下Fielddata
Fielddata
doc values不生成分析的字符串,那为什么这些字段仍然可以使用聚合呢?是因为使用了fielddata的数据结构。与doc values不同,fielddata构建和管理100%在内存中,常驻于JVM内存堆。
从历史上看,fielddata 是所有字段的默认设置。但是Elasticsearch已迁移到doc values以减少 OOM 的几率。分析的字符串是仍然使用fielddata的最后一块阵地。 最终目标是建立一个序列化的数据结构类似于doc values ,可以处理高维度的分析字符串,逐步淘汰 fielddata。
它的一些特性如下
- 延迟加载。如果你从来没有聚合一个分析字符串,就不会加载fielddata到内存中,其是在查询时候构建的。
- 基于字段加载。 只有很活跃地使用字段才会增加fielddata的负担。
- 会加载索引中(针对该特定字段的) 所有的文档,而不管查询是否命中。逻辑是这样:如果查询会访问文档 X、Y 和 Z,那很有可能会在下一个查询中访问其他文档。
- 如果空间不足,使用最久未使用(LRU)算法移除fielddata。
因此,在聚合字符串字段之前,请评估情况:
- 这是一个
not_analyzed字段吗?如果是,可以通过doc values节省内存 。 - 否则,这是一个
analyzed字段,它将使用fielddata并加载到内存中。这个字段因为N-grams有一个非常大的基数?如果是,这对于内存来说极度不友好。
索引压缩
FOR编码
在Elasticsearch中,为了能够更方便的计算交集和并集,它要求倒排索引是有序的,而这个特点同时也带来了一个额外的好处,我们可以使用增量编码来压缩倒排索引,也就是FOR(Frame of Reference)编码
增量编码压缩,将大数变小数,按字节存储
FOR编码分为三个步骤
- 增量编码
- 增量分区
- 位压缩
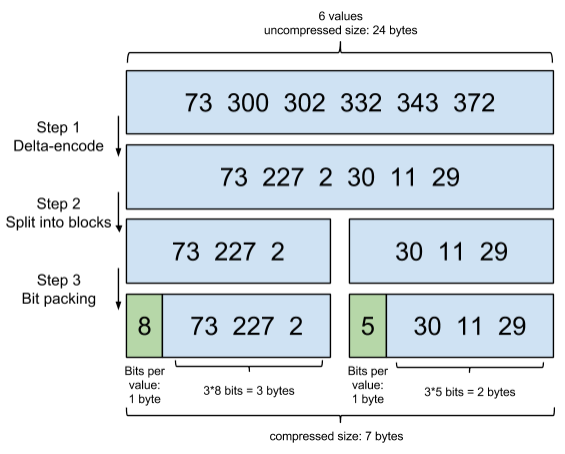
如下图所示,如果我们的倒排索引中存储的文档id为[73, 300, 302, 332, 343, 372],那么经过增量编码后的结果则为[73, 227, 2, 30, 11, 29]。这种压缩的好处在哪里呢?我们通过增量将原本的大数变成了小数,使得所有的增量都在0~255之间,因此每一个值就只需要使用一个字节就可以存储,而不会使用int或者bigint,大大的节约了空间。
接着,第二步我们将这些增量分到不同的区块中(Lucene底层用了256个区块,下面为了方便展示之用了两个)。
第三步,我们计算出每组数据中最大的那个数所占用的bit位数,例如下图中区块1最大的为227,所以只占用8个bit位,所以三个数总共占用3 * 8bits即3字节。而区块2最大为29,只占用5个bit位,因此这三个数总共占用3 * 5bits即差不多2字节。通过这种方法,将原本6个整数从24字节压缩到了5字节,效果十分出色。
Roaring Bitmaps
FOR编码对于倒排索引来说效果很好,但对于需要存储在内存中的过滤器缓存等不太合适,两者之间有很多不同之处:
- 由于我们仅仅缓存那些经常使用的过滤器,因此它的压缩率并不需要像倒排索引那么高(倒排索引需要对每个词都进行编码)。
- 缓存过滤器的目的就是为了加速处理效率,因此它必须要比重新执行过滤器要快,因此使用一个好的数据结构和算法非常重要。
- 缓存的过滤器存储在内存之中,而倒排索引通常存储在磁盘中。
基于以上的不同,对于缓存来说FOR编码并不适用,因此我们还需要考虑其他的一些选择。
- 整数数组:数组可能是我们马上能想到的最简单的实现方式,我们将文档id存储在数组中,这样就使得我们的迭代变得非常简单,但是这种方法的内存利用率又十分低下,因为每个文档都需要4个字节。
- Bitmaps:在数据分布密集的下,位图是一个很好的选择。它本质上就是一个数组,其中每一个文档id占据一个位,用0和1来标记文档是否存在。这种方法大大节约了内存,将一个文档从4字节降低到了一个位,但是一旦数据分布稀疏,此时的位图性能将大打折扣,因为无论数据量多少,位图的大小都是由数据的上下区间来决定的。
- Roaring Bitmaps:Roaring Bitmaps即是对位图的一种优化,它会根据16位最高位将倒排索引划分为多块,如第一个块将对0到65535之间的值进行编码,第二个块将在65536和131071之间进行编码。在每一个块中,我们再对低16位进行编码,如果它的值小于4096在使用数组,否则就使用位图。由于我们编码的时候只会对低16位进行编码,因此在这里数组每个元素只需要2个字节
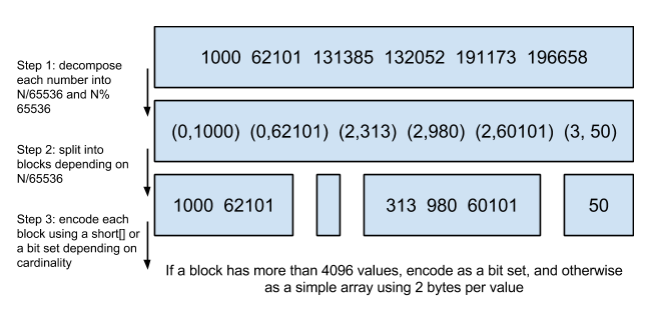
为什么要使用4096作为数组和位图选取的阈值呢?
下面是官方给出的数据报告,在一个块中只有文档数量超过4096,位图的内存优势才会凸显出来
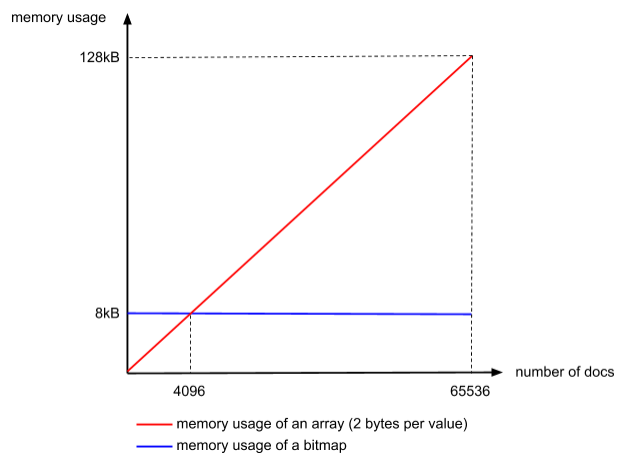
这就是Roaring Bitmaps高效率的原因,它基于两种完全不同的方案来进行编码,并根据内存效率来动态决定使用哪一种方案。
官方也给出了几种方案的性能测试
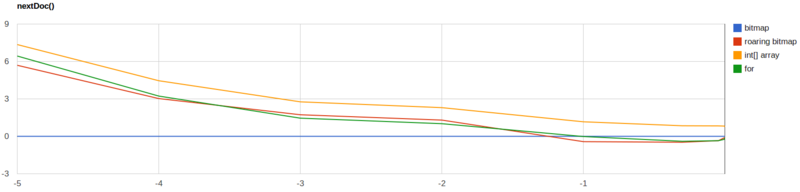
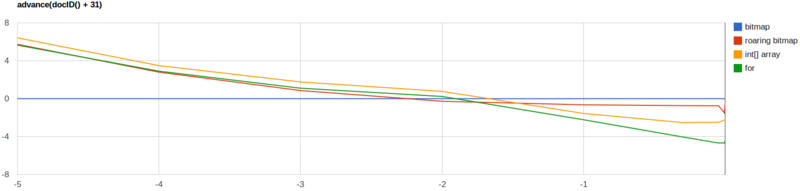
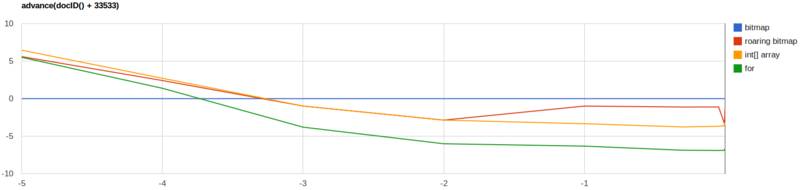
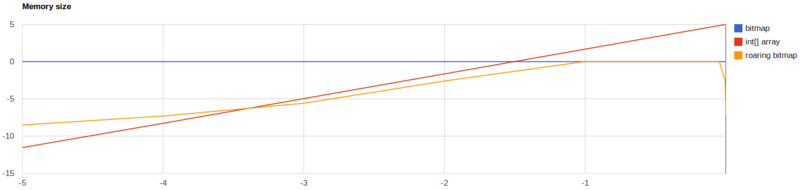
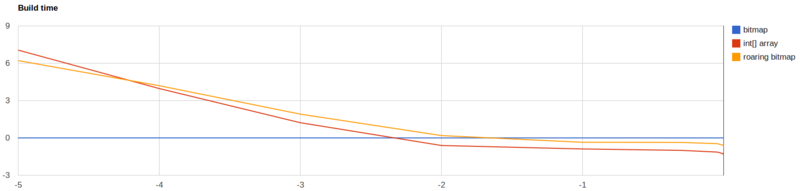
从上述对比可以看出,没有一种方法是完美的,但是以下两种方法的巨大劣势使得它们不会被选择
- 数组:性能很好,但是内存占用巨大。
- Bitmaps:数据稀疏分布的时候内存和性能都会大打折扣。
因此在综合考量下,Elasticsearch还是选择使用Roaring Bitmaps,并且在很多大家了解的开源大数据框架中,也都使用了这一结构,如Hive、Spark、Kylin、Druid等。
联合索引
如果多个字段索引的联合查询,倒排索引如何满足快速查询的要求呢?
- 跳表:同时遍历多个字段的倒排索引,互相skip。
- 位图:对多个过滤器分别求出位图,对这几个位图做
AND操作。
Elasticsearch支持以上两种的联合索引方式,如果查询的过滤器缓存到了内存中(以位图的形式),那么合并就是两个位图的AND。如果查询的过滤器没有缓存,那么就用跳表的方式去遍历两个硬盘中的倒排索引。
假设有下面三个倒排索引需要联合索引:
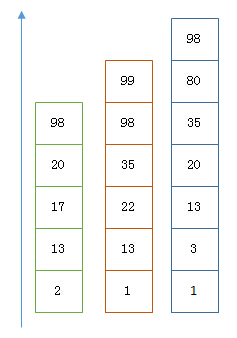
- 如果使用跳表,则对最短的倒排索引中的每一个id,逐个在另外两个倒排索引中查看是否存在,来判断是否存在交集。
- 如果使用位图,则直接将几个位图按位与运算,最终得到的结果就是最后的交集。