公共基础类
内存管理
Arena
内存频繁创建/释放的地方就会有内存池的出现,LevelDB 也不例外。在 Memtable 组件中,会有大量内存创建(数据持续 put)和释放(dump 到磁盘后内存结束),于是 LevelDB 通过 Arena 来管理内存。
它有什么好处呢?
- 提升性能:内存申请本身就需要占用一定的资源,消耗空间与时间。而 Arena 内存池的基本思路就是预先申请一大块内存,然后多次分配给不同的对象,从而减少
malloc 或 new 的调用次数。
- 提高内存利用率:频繁进行内存的申请与释放易造成内存碎片。即内存余量虽然够用,但由于缺乏足够大的连续空闲空间,从而造成申请一段较大的内存不成功的情况。而 Arena 具有整块内存的控制权,用户可以任意操作这段内存,从而避免内存碎片的产生。
结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
// https://github.com/google/leveldb/blob/master/util/arena.h
class Arena {
public:
Arena();
Arena(const Arena&) = delete;
Arena& operator=(const Arena&) = delete;
~Arena();
char* Allocate(size_t bytes);
malloc.
char* AllocateAligned(size_t bytes);
size_t MemoryUsage() const {
return memory_usage_.load(std::memory_order_relaxed);
}
private:
char* AllocateFallback(size_t bytes);
char* AllocateNewBlock(size_t block_bytes);
char* alloc_ptr_;
size_t alloc_bytes_remaining_;
std::vector<char*> blocks_;
std::atomic<size_t> memory_usage_;
};
|
其组成如下:
- 成员变量
- alloc_ptr_ :当前已使用内存的指针
- blocks_ :实际分配的内存池_
- alloc_bytes_remaining_ :剩余内存字节数
- memory_usage_ :记录内存的使用情况
- kBlockSize :一个块大小(默认4k)
- 成员函数
- AllocateFallback :按需分配内存,可能会有内存浪费。
- AllocateAligned :分配偶数大小的内存,主要是 skiplist 节点时,目的是加快访问。
- MemoryUsage:统计内存使用量。
内存分配
Arena 中与内存分配有关的两个接口函数:Allocate 与 AllocateAligned。
首先我们来看看 Allocate 与它依赖的两个函数 AllocateFallback 与 AllocateNewBlock。代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
|
// https://github.com/google/leveldb/blob/master/util/arena.h
inline char* Arena::Allocate(size_t bytes) {
assert(bytes > 0);
if (bytes <= alloc_bytes_remaining_) {
char* result = alloc_ptr_;
alloc_ptr_ += bytes;
alloc_bytes_remaining_ -= bytes;
return result;
}
return AllocateFallback(bytes);
}
|
首先,对于 Allocate 来说,它存在两种情况
- 需要分配的字节数小于等于 alloc_bytes_remaining_:
Allocate 直接返回 alloc_ptr_ 指向的地址空间,然后对 alloc_ptr_ 与 alloc_bytes_remaining_ 进行更新。
- 需要分配的字节数大于 alloc_bytes_remaining_:调用
AllocateFallback 方法进行扩容。
AllocateFallback 用于申请一个新 Block 内存空间,然后分配需要的内存并返回。因此当前 Block 剩余空闲内存就不可避免地浪费了。接着看看 AllocateFallback 的逻辑
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
// https://github.com/google/leveldb/blob/master/util/arena.cc
char* Arena::AllocateFallback(size_t bytes) {
if (bytes > kBlockSize / 4) {
char* result = AllocateNewBlock(bytes);
return result;
}
alloc_ptr_ = AllocateNewBlock(kBlockSize);
alloc_bytes_remaining_ = kBlockSize;
char* result = alloc_ptr_;
alloc_ptr_ += bytes;
alloc_bytes_remaining_ -= bytes;
return result;
}
|
AllocateFallback 的使用也包括两种情况:
- 需要分配的空间大于 kBlockSize 的 1/4(即1024字节):直接申请需要分配空间大小的 Block,从而避免剩余内存空间的浪费。
- 需要分配的空间小于等于 kBlockSize 的 1/4 :申请一个大小为 kBlockSize 的新 Block 空间,然后在新的Block上分配需要的内存并返回其首地址。
对于 Block 的分配,这里又调用了 AllocateNewBlock,其逻辑如下:
1
2
3
4
5
6
7
8
9
|
// https://github.com/google/leveldb/blob/master/util/arena.cc
char* Arena::AllocateNewBlock(size_t block_bytes) {
char* result = new char[block_bytes];
blocks_.push_back(result);
memory_usage_.fetch_add(block_bytes + sizeof(char*),
std::memory_order_relaxed);
return result;
}
|
这里的逻辑非常简单,其通过 new,申请了一段大小为 block_bytes 的内存空间,并将这块空间的地址存储到 blocks_ 中,之后更新当前可用的总空间大小后将空间首地址返回。
讲解完了 Allocate ,我们接着再来看看 AllocateAligned。虽然它也用于内存分配,但不同点在于它考虑了内存分配时的内存对齐问题(进行内存分配所返回的起始地址应为 b / 8 的倍数,在这里 b 代表操作系统平台的位数)。代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
// https://github.com/google/leveldb/blob/master/util/arena.cc
char* Arena::AllocateAligned(size_t bytes) {
const int align = (sizeof(void*) > 8) ? sizeof(void*) : 8;
static_assert((align & (align - 1)) == 0,
"Pointer size should be a power of 2");
size_t current_mod = reinterpret_cast<uintptr_t>(alloc_ptr_) & (align - 1);
size_t slop = (current_mod == 0 ? 0 : align - current_mod);
size_t needed = bytes + slop;
char* result;
if (needed <= alloc_bytes_remaining_) {
result = alloc_ptr_ + slop;
alloc_ptr_ += needed;
alloc_bytes_remaining_ -= needed;
} else {
// AllocateFallback always returned aligned memory
result = AllocateFallback(bytes);
}
assert((reinterpret_cast<uintptr_t>(result) & (align - 1)) == 0);
return result;
}
|
由于主流的服务器平台采用 64 位的操作系统,64位 操作系统的指针同样为 64 位(即 8 个字节),因此这里的对齐就需要使分配的内存起始地址必然为 8 的倍数。要满足这一条件,采用的主要办法就是判断当前空闲内存的起始地址是否为 8 的倍数:如果是,则直接返回;如果不是,则对 8 求模,然后向后寻找最近的 8 的倍数的内存地址并返回。
由于计算机进行乘除或求模运算的速度远慢于位操作运算,因此这里巧妙的用了位运算来进行优化。
- 用位运算判断某个数值是否为2的正整数幂:
static_assert((align & (align - 1)) == 0, "Pointer size should be a power of 2");
- 用位运算进行求模:
size_t current_mod = reinterpret_cast<uintptr_t>(alloc_ptr_) & (align - 1);
位运算的细节这里就i不提了,大家可以自行百度了解。
内存使用率统计
memory_usage_ 用于存储当前 Arena 所申请的总共的内存空间大小,为了保证线程安全,其为 atomic<size_t> 变量。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
// https://github.com/google/leveldb/blob/master/util/arena.h
size_t MemoryUsage() const {
return memory_usage_.load(std::memory_order_relaxed);
}
// https://github.com/google/leveldb/blob/master/util/arena.cc
char* Arena::AllocateNewBlock(size_t block_bytes) {
char* result = new char[block_bytes];
blocks_.push_back(result);
memory_usage_.fetch_add(block_bytes + sizeof(char*),
std::memory_order_relaxed);
return result;
}
|
在 AllocateNewBock 申请内存的过程中,其会通过以下的公式来更新当前总大小
memory_usage_ = memory_usage_ + block_bytes + sizeof(char*)
为什么这里还需要加上一个sizeof(char*)呢?
因为在申请完 Block 后,Block 的首地址需要存储在一个 vector<char*> 的动态数组 blocks_ 中,因而需要额外占用一个指针的空间。
TCMalloc
LevelDB 中针对一些需要调用 new 或 malloc 方法进行堆内存操作的情况(即非内存池的内存分配),其使用 TCMalloc 进行优化。
TCMalloc(Thread-Caching Malloc)是 google-perftool 中一个管理堆内存的内存分配器工具,可以降低内存频繁分配与释放所造成的性能损失,并有效控制内存碎片。默认 C/C++ 在编译器中主要采用 glibc 的内存分配器 ptmalloc2。同样的 malloc 操作,TCMalloc 比 ptmalloc2 更具性能优势。
TCMalloc 的详细介绍可以参见http://goog-perftools.sourceforge.net/doc/tcmalloc.html。
Env家族
Env 是一个抽象接口类,用纯虚函数的形式定义了一些与平台操作的相关接口,如文件系统、多线程、时间操作等。接口定义如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
|
// https://github.com/google/leveldb/blob/master/include/leveldb/env.h
class LEVELDB_EXPORT Env {
public:
Env();
Env(const Env&) = delete;
Env& operator=(const Env&) = delete;
virtual ~Env();
static Env* Default();
virtual Status NewSequentialFile(const std::string& fname,
SequentialFile** result) = 0;
virtual Status NewRandomAccessFile(const std::string& fname,
RandomAccessFile** result) = 0;
virtual Status NewWritableFile(const std::string& fname,
WritableFile** result) = 0;
virtual Status NewAppendableFile(const std::string& fname,
WritableFile** result);
virtual bool FileExists(const std::string& fname) = 0;
virtual Status GetChildren(const std::string& dir,
std::vector<std::string>* result) = 0;
virtual Status RemoveFile(const std::string& fname);
virtual Status DeleteFile(const std::string& fname);
virtual Status CreateDir(const std::string& dirname) = 0;
virtual Status RemoveDir(const std::string& dirname);
virtual Status DeleteDir(const std::string& dirname);
virtual Status GetFileSize(const std::string& fname, uint64_t* file_size) = 0;
virtual Status RenameFile(const std::string& src,
const std::string& target) = 0;
virtual Status LockFile(const std::string& fname, FileLock** lock) = 0;
virtual Status UnlockFile(FileLock* lock) = 0;
virtual void Schedule(void (*function)(void* arg), void* arg) = 0;
virtual void StartThread(void (*function)(void* arg), void* arg) = 0;
virtual Status GetTestDirectory(std::string* path) = 0;
virtual Status NewLogger(const std::string& fname, Logger** result) = 0;
virtual uint64_t NowMicros() = 0;
virtual void SleepForMicroseconds(int micros) = 0;
};
|
Env 作为抽象类,有 3 个派生子类:PosixEnv、EnvWrapper 与 InMemoryEnv。
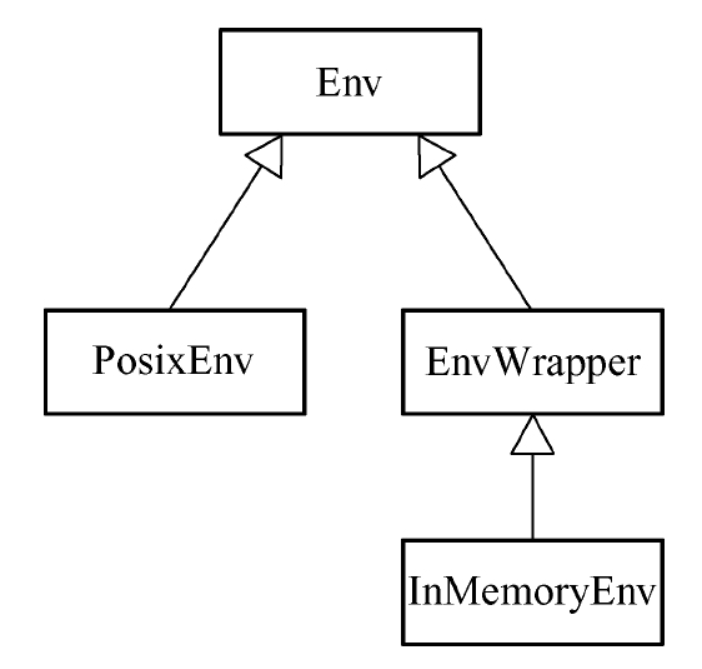
这里就不过多的介绍它们的实现原理,只是大概的描述一下概念,方便理解。
PosixEnv
PosixEnv 是 LevelDB 中默认的 Env 实例对象。从字面意思上看,PosixEnv 就是针对 POSIX 平台的 Env 接口实现。
EnvWrapper
EnvWrapper 也是 Env 的一个派生类,与 PosixEnv 不同的是,EnvWrapper 中并没有定义众多纯虚函数接口的具体实现,而是定义了一个私有成员变量 Env* target_,并在构造函数中通过传递预定义的 Env 实例对象,从而实现对 target_ 的初始化操作。基于 EnvWrapper 的派生类,易于实现用户在某一个 Env 派生类的基础上改写其中一部分接口的需求。
InMemoryEnv
InMemoryEnv 就是 EnvWrapper 的一个子类,主要对 Env 中有关文件的接口进行了重写。InMemoryEnv 主要是将所有的操作都置于内存中,从而提升文件I/O的读取速度。
文件操作
在 LevelDB 中,主要有三种文件 I/O 操作:
- SequentialFile:顺序读,如日志文件的读取、Manifest文件的读取。
- WritableFile:顺序写,用于日志文件、SSTable文件、Manifest文件的写入。
- RandomAccessFile:随机读,如SSTable文件的读取。
SequentialFile
SequentialFile 定义了文件顺序读抽象接口,其接口定义如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
// https://github.com/google/leveldb/blob/master/include/leveldb/env.h
class LEVELDB_EXPORT SequentialFile {
public:
SequentialFile() = default;
SequentialFile(const SequentialFile&) = delete;
SequentialFile& operator=(const SequentialFile&) = delete;
virtual ~SequentialFile();
virtual Status Read(size_t n, Slice* result, char* scratch) = 0;
virtual Status Skip(uint64_t n) = 0;
};
|
其主要有两个接口方法,即 Read 与 Skip:
- Read:用于从文件当前位置顺序读取指定的字节数。
- Skip:用于从当前位置,顺序向后忽略指定的字节数。
无论是Read方法还是Skip方法,对于多线程环境而言均不是线程安全的访问方法,需要开发者在调用过程中采用外部手段进行线程同步操作。
PosixSequentialFile,是在符合POSIX标准的文件系统上对顺序读的实现。这里就不过多介绍,感兴趣的可以自己去了解。
WritableFile
WritableFile定义了文件顺序写抽象接口,其定义下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
// https://github.com/google/leveldb/blob/master/include/leveldb/env.h
class LEVELDB_EXPORT WritableFile {
public:
WritableFile() = default;
WritableFile(const WritableFile&) = delete;
WritableFile& operator=(const WritableFile&) = delete;
virtual ~WritableFile();
virtual Status Append(const Slice& data) = 0;
virtual Status Close() = 0;
virtual Status Flush() = 0;
virtual Status Sync() = 0;
};
|
WritableFile 主要有4个纯虚函数接口:Append、Close、Flush 与 Sync:
- Append:用于以追加的方式对文件顺序写入。
- Close:用于关闭文件。
- Flush:用于将
Append 操作写入到缓冲区的数据强制刷新到内核缓冲区。
- Sync:用于将内存缓冲区的数据强制保存到磁盘。
PosixWritableFile 是对符合 POSIX 标准平台的 WritableFile 的派生实现。
RandomAccessFile
随机读就是指可以定位到文件任意某个位置进行读取。RandomAccessFile 是文件随机读的抽象接口,其代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
// https://github.com/google/leveldb/blob/master/include/leveldb/env.h
class LEVELDB_EXPORT RandomAccessFile {
public:
RandomAccessFile() = default;
RandomAccessFile(const RandomAccessFile&) = delete;
RandomAccessFile& operator=(const RandomAccessFile&) = delete;
virtual ~RandomAccessFile();
virtual Status Read(uint64_t offset, size_t n, Slice* result,
char* scratch) const = 0;
};
|
与顺序读接口相比,随机读没有 Skip 操作,只有一个 Read 方法:
- Read:可从文件指定的任意位置读取一段指定长度数据。
在 LevelDB 中,RandomAccessFile 有两个派生类:PosixRandomAccessFile 与 PosixMmapReadableFile。这两个派生类是两种对随机文件操作的实现形式:一种是基于 pread() 方法的随机访问;另一种是基于 mmap() 方法的随机访问。
数值编码
LevelDB 是一个嵌入式的存储库,其存储的内容可以是字符,也可以是数值。LevelDB 为了减少数值型内容对内存空间的占用,分别针对不同的需求定义了两种编码方式:一种是定长编码,另一种是变长编码。
字节序
在讲编码之前,先聊聊字节序。字节序是处理器架构的特性,比如一个16 位的整数,他是由 2 个字节组成。内存中存储 2 个字节有两种方法:
- 将低序字节存储在起始地址,称为小端。
- 将高序字节存储在起始地址,称为大端。
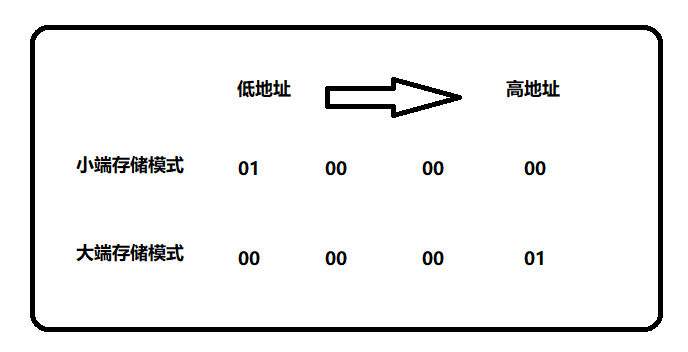
LevelDB 为了便于操作,编码的数据统一采用小端模式,并存放到对应的字符串中,即数据低位存在内存低地址,数据高位存在内存高地址。
具体的关于大小端的信息可以参考往期博客 大端小端存储解析以及判断方法。
定长编码
定长的数值编码比较简单,主要是将原有的 uint64 或 uint32 的数据直接存储在对应的 8 字节或 4 字节中。而在直接存储的过程中,会基于大小端的不同,采取不同的执行逻辑(新版代码简化逻辑,统一按照大端逻辑处理):
- 大端:在复制过程中调换字节顺序,以小端模式进行编码保存。
- 小端:直接利用
memcpy 进行内存间的复制。
具体实现代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
|
// https://github.com/google/leveldb/blob/master/util/coding.h
//32位数据定长编码
void EncodeFixed32(char* buf, uint32_t value) {
if (port::kLittleEndian) {
memcpy(buf, &value, sizeof(value));
} else {
buf[0] = value & 0xff;
buf[1] = (value >> 8) & 0xff;
buf[2] = (value >> 16) & 0xff;
buf[3] = (value >> 24) & 0xff;
}
}
//64位数据定长编码
void EncodeFixed64(char* buf, uint64_t value) {
if (port::kLittleEndian) {
memcpy(buf, &value, sizeof(value));
} else {
buf[0] = value & 0xff;
buf[1] = (value >> 8) & 0xff;
buf[2] = (value >> 16) & 0xff;
buf[3] = (value >> 24) & 0xff;
buf[4] = (value >> 32) & 0xff;
buf[5] = (value >> 40) & 0xff;
buf[6] = (value >> 48) & 0xff;
buf[7] = (value >> 56) & 0xff;
}
}
//32位数据定长解码
inline uint32_t DecodeFixed32(const char* ptr) {
if (port::kLittleEndian) {
// Load the raw bytes
uint32_t result;
memcpy(&result, ptr, sizeof(result)); // gcc optimizes this to a plain load
return result;
} else {
return ((static_cast<uint32_t>(static_cast<unsigned char>(ptr[0])))
| (static_cast<uint32_t>(static_cast<unsigned char>(ptr[1])) << 8)
| (static_cast<uint32_t>(static_cast<unsigned char>(ptr[2])) << 16)
| (static_cast<uint32_t>(static_cast<unsigned char>(ptr[3])) << 24));
}
}
//64位数据定长解码
inline uint64_t DecodeFixed64(const char* ptr) {
if (port::kLittleEndian) {
// Load the raw bytes
uint64_t result;
memcpy(&result, ptr, sizeof(result)); // gcc optimizes this to a plain load
return result;
} else {
uint64_t lo = DecodeFixed32(ptr);
uint64_t hi = DecodeFixed32(ptr + 4);
return (hi << 32) | lo;
}
}
|
变长编码
对于 4 字节或 8 字节表示的无符号整型数据而言,数值较小的整数的高位空间基本为 0,如 uint32 类型的数据 128,高位的 3 个字节都是 0。为了更好的利用这些高位空间,如果能基于某种机制,将为 0 的高位数据忽略,有效地保留其有效位,从而减少所需字节数、节约存储空间。于是 LevelDB 就采用了 Google 的另一个开源项目 Protobuf 中提出的 varint 变长编码。
**varint 将实际的一个字节分成了两个部分,最高位定义为 MSB(mostsignificant bit),后续低 7 位表示实际数据。**MSB 是一个标志位,用于表示某一数值的字节是否还有后续的字节,如果为 1 表示该数值后续还有字节,如果为 0 表示该数值所编码的字节至此完毕。每一个字节中的第 1 到第 7 位表示的是实际的数据,由于有 7 位,则只能表示大小为 0~127 的数值。
下图给出了 127、300、2^28 - 1 的编码结果
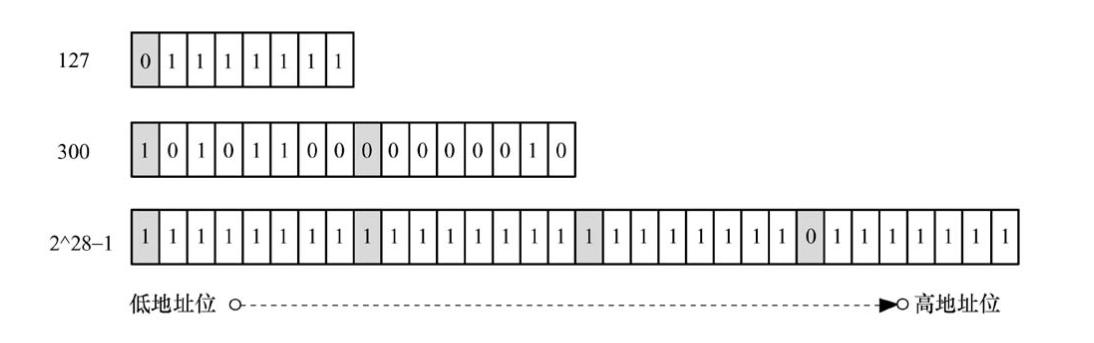
具体实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
// https://github.com/google/leveldb/blob/master/util/coding.cc
//32位数据变长编码
char* EncodeVarint32(char* dst, uint32_t v) {
// Operate on characters as unsigneds
uint8_t* ptr = reinterpret_cast<uint8_t*>(dst);
static const int B = 128;
if (v < (1 << 7)) {
*(ptr++) = v;
} else if (v < (1 << 14)) {
*(ptr++) = v | B;
*(ptr++) = v >> 7;
} else if (v < (1 << 21)) {
*(ptr++) = v | B;
*(ptr++) = (v >> 7) | B;
*(ptr++) = v >> 14;
} else if (v < (1 << 28)) {
*(ptr++) = v | B;
*(ptr++) = (v >> 7) | B;
*(ptr++) = (v >> 14) | B;
*(ptr++) = v >> 21;
} else {
*(ptr++) = v | B;
*(ptr++) = (v >> 7) | B;
*(ptr++) = (v >> 14) | B;
*(ptr++) = (v >> 21) | B;
*(ptr++) = v >> 28;
}
return reinterpret_cast<char*>(ptr);
}
//32位数据变长解码
const char* GetVarint32PtrFallback(const char* p, const char* limit,
uint32_t* value) {
uint32_t result = 0;
for (uint32_t shift = 0; shift <= 28 && p < limit; shift += 7) {
uint32_t byte = *(reinterpret_cast<const uint8_t*>(p));
p++;
if (byte & 128) {
// More bytes are present
result |= ((byte & 127) << shift);
} else {
result |= (byte << shift);
*value = result;
return reinterpret_cast<const char*>(p);
}
}
return nullptr;
}
|