版本管理
为什么 LevelDB 需要版本的概念呢?
针对共享的资源,有三种方式:
- 悲观锁:这是最简单的处理方式。加锁保护,读写互斥。效率低。
- 乐观锁:它假设多用户并发的事物在处理时不会彼此互相影响,各事务能够在不产生锁的的情况下处理各自影响的那部分数据。在提交数据更新之前,每个事务会先检查在该事务读取数据后,有没有其他事务又修改了该数据。 果其他事务有更新的话,正在提交的事务会进行回滚;这样做不会有锁竞争更不会产生死锁, 但如果数据竞争的概率较高,效率也会受影响 。
- MVCC:MVCC 是一个数据库常用的概念。Multi Version Concurrency Control 多版本并发控制。每一个执行操作的用户,看到的都是数据库特定时刻的的快照 (Snapshot), Writer 的任何未完成的修改都不会被其他的用户所看到;当对数据进行更新的时候并是不直接覆盖,而是先进行标记,然后在其他地方添加新的数据(这些变更存储在 VersionEdit),从而形成一个新版本,此时再来读取的 Reader 看到的就是最新的版本了。所以这种处理策略是维护了多个版本的数据的,但只有一个是最新的(VersionSet 中维护着全局最新的 Seqnum)。
LevelDB 通过 Version 以及 VersionSet 来管理元信息,用 Manifest 来保存元信息。
Manifest
Manifest 文件专用于记录版本信息。LevelDB 采用了增量式的存储方式,记录每一个版本相较于一个版本的变化情况。
变化情况大致包括:
(1)新增了哪些 SSTable 文件;
(2)删除了哪些 SSTable 文件(由于Compaction导致);
(3)最新的 Journal 日志文件标号等;
一个 Manifest 文件中,包含了多条 Session Record。其中第一条 Session Record 记载了当时 LevelDB 的全量版本信息,其余若干条 Session Record 仅记录每次更迭的变化情况。具体结构如下图:
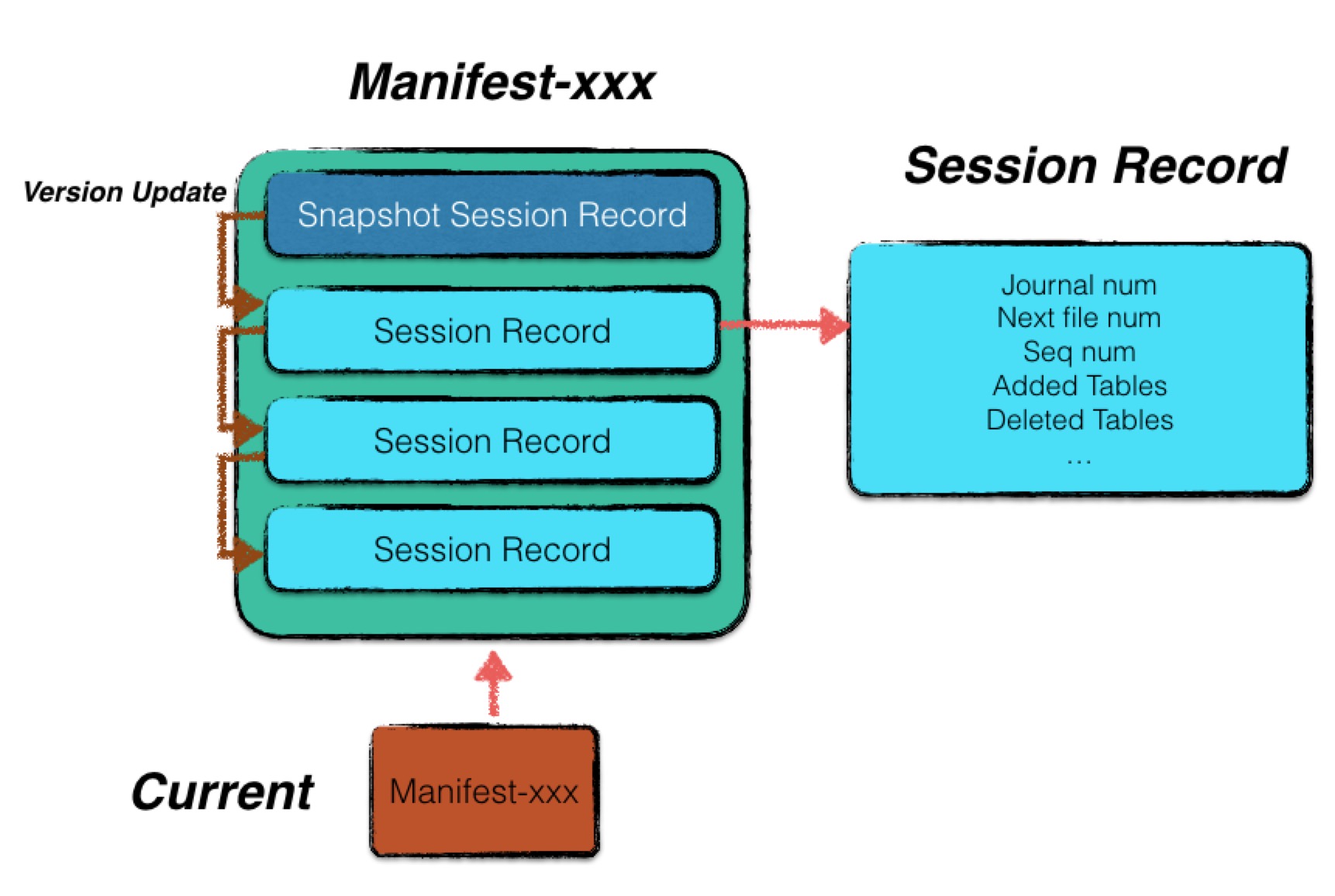
LevelDB 启动时会先到数据目录寻找一个名为 CURRENT 的文件,该文件中会保存 Manifest 的文件名称,通过读取 Manifest 记录的 Session Record,从初始状态开始不断地应用这些版本改动,即可使得系统的版本信息恢复到最近一次使用的状态。
Version
Version 表示当前的一个版本,该结构中会保存每个层级拥有的文件信息以及指向前一个和后一个版本的指针等。
结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
|
class Version {
public:
struct GetStats {
FileMetaData* seek_file;
int seek_file_level;
};
void AddIterators(const ReadOptions&, std::vector<Iterator*>* iters);
Status Get(const ReadOptions&, const LookupKey& key, std::string* val,
GetStats* stats);
bool UpdateStats(const GetStats& stats);
bool RecordReadSample(Slice key);
void Ref();
void Unref();
void GetOverlappingInputs(
int level,
const InternalKey* begin, // nullptr means before all keys
const InternalKey* end, // nullptr means after all keys
std::vector<FileMetaData*>* inputs);
bool OverlapInLevel(int level, const Slice* smallest_user_key,
const Slice* largest_user_key);
int PickLevelForMemTableOutput(const Slice& smallest_user_key,
const Slice& largest_user_key);
int NumFiles(int level) const { return files_[level].size(); }
std::string DebugString() const;
private:
friend class Compaction;
friend class VersionSet;
class LevelFileNumIterator;
explicit Version(VersionSet* vset)
: vset_(vset),
next_(this),
prev_(this),
refs_(0),
file_to_compact_(nullptr),
file_to_compact_level_(-1),
compaction_score_(-1),
compaction_level_(-1) {}
Version(const Version&) = delete;
Version& operator=(const Version&) = delete;
~Version();
Iterator* NewConcatenatingIterator(const ReadOptions&, int level) const;
void ForEachOverlapping(Slice user_key, Slice internal_key, void* arg,
bool (*func)(void*, int, FileMetaData*));
VersionSet* vset_; // VersionSet to which this Version belongs
Version* next_; // Next version in linked list
Version* prev_; // Previous version in linked list
int refs_; // Number of live refs to this version
std::vector<FileMetaData*> files_[config::kNumLevels];
FileMetaData* file_to_compact_;
int file_to_compact_level_;
double compaction_score_;
int compaction_level_;
};
struct FileMetaData {
FileMetaData() : refs(0), allowed_seeks(1 << 30), file_size(0) {}
int refs; // 引用计数
int allowed_seeks; // 用于seek compaction
uint64_t number; // 唯一标识一个sstable
uint64_t file_size; // 文件大小
InternalKey smallest; // 最小key
InternalKey largest; // 最大key
};
|
- 成员变量:
- GetStats:键查找时用来保存中间状态的一个结构。
- vset_:该版本属于的版本集合。
- next_:指向后一个版本的指针。
- prev_:指向前一个版本的指针。
- refs_:该版本的引用计数。
- files_:每个层级所包含的 SSTable 文件,每一个文件以一个 FileMetaData 结构表示。
- file_to_compact_:下次需要进行 Compaction 操作的文件。
- file_to_compact_level_:下次需要进行 Compaction 操作的文件所属的层级。
- compaction_score_:如果 compaction_score_ 大于 1,说明需要进行一次 Compaction 操作。
- compaction_level_:表明需要进行 Compaction 操作的层级。
VersionEdit
**VersionEdit 是一个版本的中间状态,会保存一次 Compaction 操作后增加的删除文件信息以及其他一些元数据。**当数据库正常/非正常关闭,重新打开时,只需要按顺序把 Manifest 文件中的 VersionEdit 执行一遍,就可以把数据恢复到宕机前的最新版本。
结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
|
// https://github.com/google/leveldb/blob/master/db/version_edit.h
class VersionEdit {
public:
VersionEdit() { Clear(); }
~VersionEdit() = default;
void Clear();
void SetComparatorName(const Slice& name) {
has_comparator_ = true;
comparator_ = name.ToString();
}
void SetLogNumber(uint64_t num) {
has_log_number_ = true;
log_number_ = num;
}
void SetPrevLogNumber(uint64_t num) {
has_prev_log_number_ = true;
prev_log_number_ = num;
}
void SetNextFile(uint64_t num) {
has_next_file_number_ = true;
next_file_number_ = num;
}
void SetLastSequence(SequenceNumber seq) {
has_last_sequence_ = true;
last_sequence_ = seq;
}
void SetCompactPointer(int level, const InternalKey& key) {
compact_pointers_.push_back(std::make_pair(level, key));
}
void AddFile(int level, uint64_t file, uint64_t file_size,
const InternalKey& smallest, const InternalKey& largest) {
FileMetaData f;
f.number = file;
f.file_size = file_size;
f.smallest = smallest;
f.largest = largest;
new_files_.push_back(std::make_pair(level, f));
}
void RemoveFile(int level, uint64_t file) {
deleted_files_.insert(std::make_pair(level, file));
}
void EncodeTo(std::string* dst) const;
Status DecodeFrom(const Slice& src);
std::string DebugString() const;
private:
friend class VersionSet;
typedef std::set<std::pair<int, uint64_t>> DeletedFileSet;
std::string comparator_;
uint64_t log_number_; //已经弃用
uint64_t prev_log_number_;
uint64_t next_file_number_;
SequenceNumber last_sequence_;
bool has_comparator_;
bool has_log_number_;
bool has_prev_log_number_;
bool has_next_file_number_;
bool has_last_sequence_;
std::vector<std::pair<int, InternalKey>> compact_pointers_;
DeletedFileSet deleted_files_;
std::vector<std::pair<int, FileMetaData>> new_files_;
};
|
- 成员变量:
- comparator_:比较器名称。
- log_number_:日志文件序号。
- **next_file_number_:**下一个文件序列号。
- last_sequence_:下一个写入序列号。
- has_xxxxx_:has_comparator_ ,has_log_number_ ,has_prev_log_number_ ,has_last_sequence_ ,has_next_file_number_,布尔型变量,表明相应的成员变量是否已经设置。
- compact_pointers_:该变量用来指示 LevelDB 中每个层级下一次进行 Compaction 操作时需要从哪个键开始。
- **deleted_files_:**记录每个层级执行 Compaction 操作之后删除掉的文件。
- new_files_:记录每个层级执行 Compaction 操作之后新增的文件。新增文件记录为一个个FileMetaData 结构体。
EncodeTo
EncodeTo 会将 VersionEdit 各个成员变量的信息编码为一个字符串,编码时会先给每个成员变量定义一个 Tag,Tag的枚举值如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
// https://github.com/google/leveldb/blob/master/db/version_edit.cc
enum Tag {
kComparator = 1, //比较器
kLogNumber = 2, //日志文件序列号
kNextFileNumber = 3, //下一个文件序列号
kLastSequence = 4, //下一个写入序列号
kCompactPointer = 5, //CompactPointer类型
kDeletedFile = 6, //删除的文件
kNewFile = 7, //增加的文件
// 8 曾经用于大Value的引用,现以弃用
kPrevLogNumber = 9 //前一个日志文件序列号
};
|
接下来看看 EncodeTo 的实现逻辑:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
// https://github.com/google/leveldb/blob/master/db/version_edit.cc
void VersionEdit::EncodeTo(std::string* dst) const {
//如果为true,则先将kComparator Tag编码,然后将比较器名称编码写入。
if (has_comparator_) {
PutVarint32(dst, kComparator);
PutLengthPrefixedSlice(dst, comparator_);
}
//与上面类似,就不再重复
if (has_log_number_) {
PutVarint32(dst, kLogNumber);
PutVarint64(dst, log_number_);
}
if (has_prev_log_number_) {
PutVarint32(dst, kPrevLogNumber);
PutVarint64(dst, prev_log_number_);
}
if (has_next_file_number_) {
PutVarint32(dst, kNextFileNumber);
PutVarint64(dst, next_file_number_);
}
if (has_last_sequence_) {
PutVarint32(dst, kLastSequence);
PutVarint64(dst, last_sequence_);
}
//依次将compact_pointers_中的level和Key编码
for (size_t i = 0; i < compact_pointers_.size(); i++) {
PutVarint32(dst, kCompactPointer);
PutVarint32(dst, compact_pointers_[i].first); // level
PutLengthPrefixedSlice(dst, compact_pointers_[i].second.Encode());
}
//依次将deleted_file_中的level和file number编码
for (const auto& deleted_file_kvp : deleted_files_) {
PutVarint32(dst, kDeletedFile);
PutVarint32(dst, deleted_file_kvp.first); // level
PutVarint64(dst, deleted_file_kvp.second); // file number
}
//依次将new_files_中的level和FileMetaData进行编码
for (size_t i = 0; i < new_files_.size(); i++) {
const FileMetaData& f = new_files_[i].second;
PutVarint32(dst, kNewFile);
PutVarint32(dst, new_files_[i].first); // level
//编码FileMetaData
PutVarint64(dst, f.number);
PutVarint64(dst, f.file_size);
PutLengthPrefixedSlice(dst, f.smallest.Encode());
PutLengthPrefixedSlice(dst, f.largest.Encode());
}
}
|
EncodeTo 函数会依次以 Tag 开头,将比较器名称、日志序列号、上一个日志序列号、下一个文件序列号、最后一个序列号、CompactPointers、每个层级删除的文件以及增加的文件信息保存到一个字符串中。
DecodeFrom
解码逻辑与上面的类似,根据不同的 tag 解析对应的成员变量,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
|
// https://github.com/google/leveldb/blob/master/db/version_edit.cc
Status VersionEdit::DecodeFrom(const Slice& src) {
Clear();
Slice input = src;
const char* msg = nullptr;
uint32_t tag;
// Temporary storage for parsing
int level;
uint64_t number;
FileMetaData f;
Slice str;
InternalKey key;
while (msg == nullptr && GetVarint32(&input, &tag)) {
//根据不同的tag执行对应的解码逻辑
switch (tag) {
case kComparator:
if (GetLengthPrefixedSlice(&input, &str)) {
comparator_ = str.ToString();
has_comparator_ = true;
} else {
msg = "comparator name";
}
break;
case kLogNumber:
if (GetVarint64(&input, &log_number_)) {
has_log_number_ = true;
} else {
msg = "log number";
}
break;
case kPrevLogNumber:
if (GetVarint64(&input, &prev_log_number_)) {
has_prev_log_number_ = true;
} else {
msg = "previous log number";
}
break;
case kNextFileNumber:
if (GetVarint64(&input, &next_file_number_)) {
has_next_file_number_ = true;
} else {
msg = "next file number";
}
break;
case kLastSequence:
if (GetVarint64(&input, &last_sequence_)) {
has_last_sequence_ = true;
} else {
msg = "last sequence number";
}
break;
case kCompactPointer:
if (GetLevel(&input, &level) && GetInternalKey(&input, &key)) {
compact_pointers_.push_back(std::make_pair(level, key));
} else {
msg = "compaction pointer";
}
break;
case kDeletedFile:
if (GetLevel(&input, &level) && GetVarint64(&input, &number)) {
deleted_files_.insert(std::make_pair(level, number));
} else {
msg = "deleted file";
}
break;
case kNewFile:
if (GetLevel(&input, &level) && GetVarint64(&input, &f.number) &&
GetVarint64(&input, &f.file_size) &&
GetInternalKey(&input, &f.smallest) &&
GetInternalKey(&input, &f.largest)) {
new_files_.push_back(std::make_pair(level, f));
} else {
msg = "new-file entry";
}
break;
default:
msg = "unknown tag";
break;
}
}
if (msg == nullptr && !input.empty()) {
msg = "invalid tag";
}
Status result;
if (msg != nullptr) {
result = Status::Corruption("VersionEdit", msg);
}
return result;
}
|
VersionSet
LevelDB 为了支持 MVCC,引入了 Version 和 VersionEdit 的概念,那么如何来有效的管理这些 Version 呢?于是引出了 VersionSet,VersionSet 是一个双向链表,而且整个 DB 只会有一个 VersionSet。
结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
|
class VersionSet {
public:
VersionSet(const std::string& dbname, const Options* options,
TableCache* table_cache, const InternalKeyComparator*);
VersionSet(const VersionSet&) = delete;
VersionSet& operator=(const VersionSet&) = delete;
~VersionSet();
Status LogAndApply(VersionEdit* edit, port::Mutex* mu)
EXCLUSIVE_LOCKS_REQUIRED(mu);
Status Recover(bool* save_manifest);
Version* current() const { return current_; }
uint64_t ManifestFileNumber() const { return manifest_file_number_; }
uint64_t NewFileNumber() { return next_file_number_++; }
void ReuseFileNumber(uint64_t file_number) {
if (next_file_number_ == file_number + 1) {
next_file_number_ = file_number;
}
}
int NumLevelFiles(int level) const;
int64_t NumLevelBytes(int level) const;
uint64_t LastSequence() const { return last_sequence_; }
void SetLastSequence(uint64_t s) {
assert(s >= last_sequence_);
last_sequence_ = s;
}
void MarkFileNumberUsed(uint64_t number);
uint64_t LogNumber() const { return log_number_; }
uint64_t PrevLogNumber() const { return prev_log_number_; }
Compaction* PickCompaction();
Compaction* CompactRange(int level, const InternalKey* begin,
const InternalKey* end);
int64_t MaxNextLevelOverlappingBytes();
Iterator* MakeInputIterator(Compaction* c);
bool NeedsCompaction() const {
Version* v = current_;
return (v->compaction_score_ >= 1) || (v->file_to_compact_ != nullptr);
}
void AddLiveFiles(std::set<uint64_t>* live);
uint64_t ApproximateOffsetOf(Version* v, const InternalKey& key);
struct LevelSummaryStorage {
char buffer[100];
};
const char* LevelSummary(LevelSummaryStorage* scratch) const;
private:
class Builder;
friend class Compaction;
friend class Version;
bool ReuseManifest(const std::string& dscname, const std::string& dscbase);
void Finalize(Version* v);
void GetRange(const std::vector<FileMetaData*>& inputs, InternalKey* smallest,
InternalKey* largest);
void GetRange2(const std::vector<FileMetaData*>& inputs1,
const std::vector<FileMetaData*>& inputs2,
InternalKey* smallest, InternalKey* largest);
void SetupOtherInputs(Compaction* c);
Status WriteSnapshot(log::Writer* log);
void AppendVersion(Version* v);
Env* const env_;
const std::string dbname_;
const Options* const options_;
TableCache* const table_cache_;
const InternalKeyComparator icmp_;
uint64_t next_file_number_;
uint64_t manifest_file_number_;
uint64_t last_sequence_;
uint64_t log_number_;
uint64_t prev_log_number_; // 0 or backing store for memtable being compacted
WritableFile* descriptor_file_;
log::Writer* descriptor_log_;
Version dummy_versions_; // Head of circular doubly-linked list of versions.
Version* current_; // == dummy_versions_.prev_
std::string compact_pointer_[config::kNumLevels];
};
|
- 关键成员变量:
- **next_file_number_**下一个文件序列号。
- manifest_file_number_:Manifest 文件的文件序列号。
- last_sequence_:当前最大的写入序列号。
- log_number_:Log文件的文件序列号。
- current_:当前的最新版本。
- compact_pointer_:记录每个层级下一次开始进行 Compaction 操作时需要从哪个键开始。
下面就介绍一下其中最核心的 LogAndApply 和 Recover 两个函数。
LogAndApply
当每次进行完 Compaction 操作后,需要调用并执行 VersionSet 中的 LogAndApply 写入版本变化后并生成一个新的版本。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
|
// https://github.com/google/leveldb/blob/master/db/version_set.cc
Status VersionSet::LogAndApply(VersionEdit* edit, port::Mutex* mu) {
//根据版本变化进行处理
if (edit->has_log_number_) {
assert(edit->log_number_ >= log_number_);
assert(edit->log_number_ < next_file_number_);
} else {
edit->SetLogNumber(log_number_);
}
if (!edit->has_prev_log_number_) {
edit->SetPrevLogNumber(prev_log_number_);
}
edit->SetNextFile(next_file_number_);
edit->SetLastSequence(last_sequence_);
//生成新的版本,其为上一个Version+VersionEdit
Version* v = new Version(this);
{
Builder builder(this, current_);
builder.Apply(edit);
builder.SaveTo(v);
}
//计算这个新version的compact score和compact level,算出最应该被Compact的level
Finalize(v);
std::string new_manifest_file;
Status s;
if (descriptor_log_ == nullptr) {
//这里没有必要进行unlock操作,因为只有在第一次调用,也就是打开数据库的时候才会走到这个路径里面来
assert(descriptor_file_ == nullptr);
new_manifest_file = DescriptorFileName(dbname_, manifest_file_number_);
edit->SetNextFile(next_file_number_);
s = env_->NewWritableFile(new_manifest_file, &descriptor_file_);
//此时重新开启一个新的MANIFEST文件,并将当前状态作为base状态写入快照
if (s.ok()) {
descriptor_log_ = new log::Writer(descriptor_file_);
//写入当前快照
s = WriteSnapshot(descriptor_log_);
}
}
//在MANIFEST写入磁盘时解锁(此时没必要加锁,由后台线程完成)
{
mu->Unlock();
后将其写入磁盘
if (s.ok()) {
std::string record;
edit->EncodeTo(&record);
//将版本变化写入MANIFEST
s = descriptor_log_->AddRecord(record);
if (s.ok()) {
//将MANIFEST写入磁盘文件
s = descriptor_file_->Sync();
}
if (!s.ok()) {
Log(options_->info_log, "MANIFEST write: %s\n", s.ToString().c_str());
}
}
//当产生新的Manifest时更新current
if (s.ok() && !new_manifest_file.empty()) {
s = SetCurrentFile(env_, dbname_, manifest_file_number_);
}
mu->Lock();
}
// 将新生成的版本挂在到VersionSet,并且将当前版本(current_)设置为新生成的版本。
if (s.ok()) {
AppendVersion(v);
log_number_ = edit->log_number_;
prev_log_number_ = edit->prev_log_number_;
} else {
delete v;
if (!new_manifest_file.empty()) {
delete descriptor_log_;
delete descriptor_file_;
descriptor_log_ = nullptr;
descriptor_file_ = nullptr;
env_->RemoveFile(new_manifest_file);
}
}
return s;
}
|
执行逻辑如下:
- 将当前的版本根据版本变化(VersionEdit)进行处理,然后生成一个新的版本。
- 如果是第一次调用,则创建一个新的 Manifest 文件,并将当前状态作为 base 写入。
- 调用
Finalize 算出下一次需要 Compaction 的 level。
- 将版本变化写入 Manifest,把 Manifest 写入磁盘。
- 将新生成的版本挂载到 VersionSet 中,并且将 current_ 设置为新生成的版本。
Recover
Recover 会根据 Manifest 文件中记录的每次版本变化(调用 VersionEdit 的 DecodeFrom 方法)逐次回放生成一个最新的版本。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
|
// https://github.com/google/leveldb/blob/master/db/version_set.cc
Status VersionSet::Recover(bool* save_manifest) {
struct LogReporter : public log::Reader::Reporter {
Status* status;
void Corruption(size_t bytes, const Status& s) override {
if (this->status->ok()) *this->status = s;
}
};
//读取CURRENT文件,找到Manifest文件
std::string current;
Status s = ReadFileToString(env_, CurrentFileName(dbname_), ¤t);
if (!s.ok()) {
return s;
}
if (current.empty() || current[current.size() - 1] != '\n') {
return Status::Corruption("CURRENT file does not end with newline");
}
current.resize(current.size() - 1);
std::string dscname = dbname_ + "/" + current;
SequentialFile* file;
s = env_->NewSequentialFile(dscname, &file);
if (!s.ok()) {
if (s.IsNotFound()) {
return Status::Corruption("CURRENT points to a non-existent file",
s.ToString());
}
return s;
}
bool have_log_number = false;
bool have_prev_log_number = false;
bool have_next_file = false;
bool have_last_sequence = false;
uint64_t next_file = 0;
uint64_t last_sequence = 0;
uint64_t log_number = 0;
uint64_t prev_log_number = 0;
Builder builder(this, current_);
int read_records = 0;
{
LogReporter reporter;
reporter.status = &s;
log::Reader reader(file, &reporter, true /*checksum*/,
0 /*initial_offset*/);
Slice record;
std::string scratch;
//读取versionedit并获取变更
while (reader.ReadRecord(&record, &scratch) && s.ok()) {
++read_records;
VersionEdit edit;
s = edit.DecodeFrom(record);
if (s.ok()) {
if (edit.has_comparator_ &&
edit.comparator_ != icmp_.user_comparator()->Name()) {
s = Status::InvalidArgument(
edit.comparator_ + " does not match existing comparator ",
icmp_.user_comparator()->Name());
}
}
if (s.ok()) {
builder.Apply(&edit);
}
if (edit.has_log_number_) {
log_number = edit.log_number_;
have_log_number = true;
}
if (edit.has_prev_log_number_) {
prev_log_number = edit.prev_log_number_;
have_prev_log_number = true;
}
if (edit.has_next_file_number_) {
next_file = edit.next_file_number_;
have_next_file = true;
}
if (edit.has_last_sequence_) {
last_sequence = edit.last_sequence_;
have_last_sequence = true;
}
}
}
delete file;
file = nullptr;
if (s.ok()) {
if (!have_next_file) {
s = Status::Corruption("no meta-nextfile entry in descriptor");
} else if (!have_log_number) {
s = Status::Corruption("no meta-lognumber entry in descriptor");
} else if (!have_last_sequence) {
s = Status::Corruption("no last-sequence-number entry in descriptor");
}
if (!have_prev_log_number) {
prev_log_number = 0;
}
MarkFileNumberUsed(prev_log_number);
MarkFileNumberUsed(log_number);
}
if (s.ok()) {
//生成最新版本
Version* v = new Version(this);
builder.SaveTo(v);
Finalize(v);
//加入versionset并设置current指针
AppendVersion(v);
manifest_file_number_ = next_file;
next_file_number_ = next_file + 1;
last_sequence_ = last_sequence;
log_number_ = log_number;
prev_log_number_ = prev_log_number;
//判断是否能够复用已有MANIFEST文件
if (ReuseManifest(dscname, current)) {
} else {
*save_manifest = true;
}
} else {
std::string error = s.ToString();
Log(options_->info_log, "Error recovering version set with %d records: %s",
read_records, error.c_str());
}
return s;
}
|
执行流程如下:
- 通过 current_ 获取到 Manifest,读取 Manifest 获取 base 状态。
- 读取 Manifest 文件中的 VersionEdit,并执行变更。
- 生成最终的版本,并将其加入 VersionSet,更新 current_。
- 判断是否能够复用已有 MANIFEST 文件。