DBImpl模块
Open
数据库 Open 操作主要用于创建新的 LevelDB 数据库或打开一个已存在的数据库。Open 操作的主要函数共需传递 3 个参数:两个输入参数 options 与 dbname,一个输出参数 dbptr。
首先我们来看看它的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
// https://github.com/google/leveldb/blob/master/db/db_impl.cc
Status DB::Open(const Options& options, const std::string& dbname, DB** dbptr) {
*dbptr = nullptr;
//初始化dbimpl
DBImpl* impl = new DBImpl(options, dbname);
impl->mutex_.Lock();
VersionEdit edit;
//尝试恢复之前已经存在的数据库文件中的数据
bool save_manifest = false;
Status s = impl->Recover(&edit, &save_manifest);
//判断Memtable是否为空
if (s.ok() && impl->mem_ == nullptr) {
//创建新的Log和MemTable
uint64_t new_log_number = impl->versions_->NewFileNumber();
WritableFile* lfile;
s = options.env->NewWritableFile(LogFileName(dbname, new_log_number),
&lfile);
if (s.ok()) {
edit.SetLogNumber(new_log_number);
impl->logfile_ = lfile;
impl->logfile_number_ = new_log_number;
impl->log_ = new log::Writer(lfile);
impl->mem_ = new MemTable(impl->internal_comparator_);
impl->mem_->Ref();
}
}
//判断是否需要保存Manifest文件
if (s.ok() && save_manifest) {
edit.SetPrevLogNumber(0);
edit.SetLogNumber(impl->logfile_number_);
//生成新的版本
s = impl->versions_->LogAndApply(&edit, &impl->mutex_);
}
if (s.ok()) {
//请理无用的文件
impl->RemoveObsoleteFiles();
//尝试进行Compaction
impl->MaybeScheduleCompaction();
}
impl->mutex_.Unlock();
if (s.ok()) {
assert(impl->mem_ != nullptr);
*dbptr = impl;
} else {
delete impl;
}
return s;
}
|
具体的实现流程如下图所示:
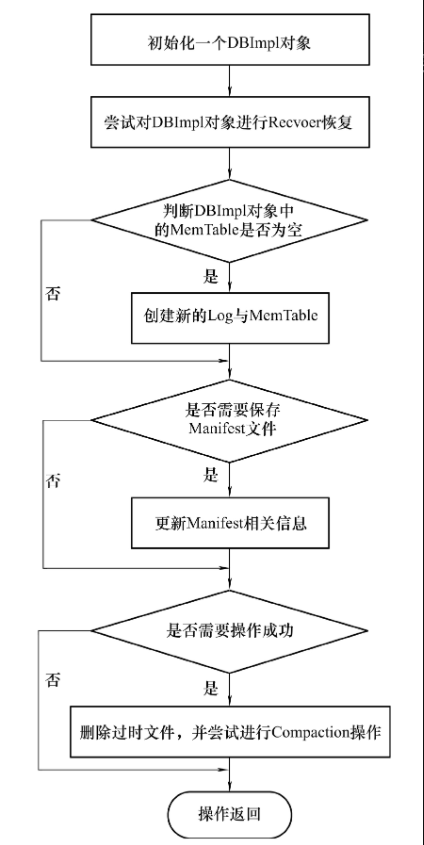
- 初始化一个 DBImpl 的对象 impl,将相关的参数选项 options 与数据库名称 dbname 作为构造函数的参数。
- 调用 DBImpl 对象的
Recover 函数,尝试恢复之前存在的数据库文件数据。
- 进行
Recover 操作后,判断 impl 对象中的 MemTable 对象指针 mem_ 是否为空,如果为空,则进入第 4 步,不为空则进入第 5 步。
- 创建新的 Log 文件以及对应的 MemTable 对象。这一步主要分别实例化 log::Writer 和 MemTable 两个对象,并赋值给 impl 中对应的成员变量,后续通过 impl 中的成员变量操作 Log 文件和 MemTable。
- 判断是否需要保存 Manifest 相关信息,如果需要,则保存相关信息。
- 判断前面步骤是否都成功了,如果成功,则调用
DeleteObsoleteFiles 函数对一些过时文件进行删除,且调用 MaybeScheduleCompaction 函数尝试进行数据文件的 Compaction 操作。
Get
Get 主要用于从 LevelDB 中获取对应的键-值对数据,它是单个数据读取的主要接口。Get 的主要参数为数据读参数选项 options、键 key,以及一个用于返回数据值的 string 类型指针 value。其代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
// https://github.com/google/leveldb/blob/master/db/db_impl.cc
Status DBImpl::Get(const ReadOptions& options, const Slice& key,
std::string* value) {
Status s;
MutexLock l(&mutex_);
SequenceNumber snapshot;
//获取序列号并赋值给snapshot
if (options.snapshot != nullptr) {
snapshot =
static_cast<const SnapshotImpl*>(options.snapshot)->sequence_number();
} else {
snapshot = versions_->LastSequence();
}
MemTable* mem = mem_;
MemTable* imm = imm_;
Version* current = versions_->current();
mem->Ref();
if (imm != nullptr) imm->Ref();
current->Ref();
bool have_stat_update = false;
Version::GetStats stats;
{
mutex_.Unlock();
//首先查找memtable
LookupKey lkey(key, snapshot);
if (mem->Get(lkey, value, &s)) {
//如果查找不到,接着查找immutable
} else if (imm != nullptr && imm->Get(lkey, value, &s)) {
//如果还是没找到,则继续查找SSTable
} else {
s = current->Get(options, lkey, value, &stats);
have_stat_update = true;
}
mutex_.Lock();
}
if (have_stat_update && current->UpdateStats(stats)) {
MaybeScheduleCompaction();
}
mem->Unref();
if (imm != nullptr) imm->Unref();
current->Unref();
return s;
}
|
具体的实现流程如下图所示:
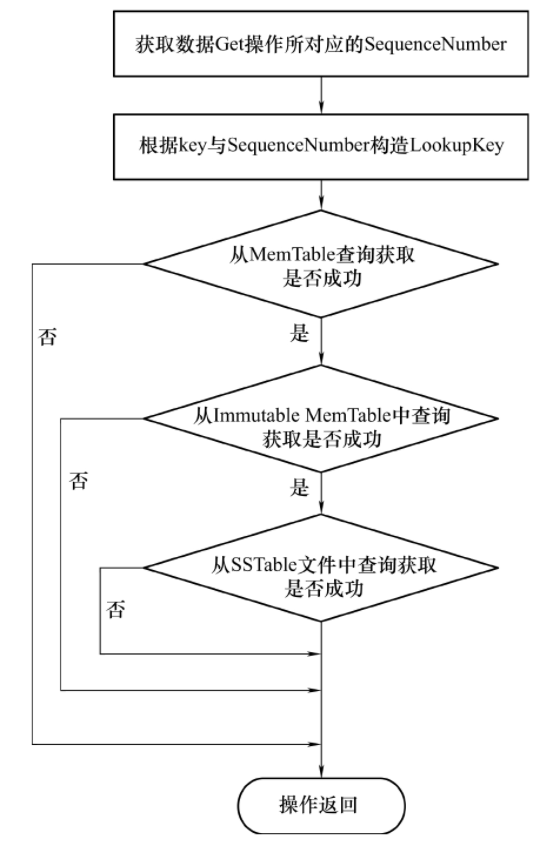
Get 在查询读取数据时,依次从 MemTable、Immutable MemTable 以及当前保存的 SSTable 文件中进行查找。如果在 MemTabel 中找到,立即返回对应的数值,如果没有找到,再从 Immutable MemTable 中查找。而如果Immutable MemTable 中还是没有找到,则会从持久化的文件 SSTable 中查找,直到找出该键对应的数值为止。
SequenceNumber 有什么用呢?
其主要作用是对 DB 的整个存储空间进行时间刻度上的序列备份,即要从 DB 中获取某一个数据,不仅需要其对应的键 key,而且需要其对应的时间序列号。对数据库进行写操作会改变序列号,每进行一次写操作,则序列号加 1。
Put、Delete、Write
Put 主要有3个参数:写操作参数 opt、操作数据的 key 与操作数据新值 value。其代码如下:
1
2
3
4
5
6
7
8
9
10
11
|
// https://github.com/google/leveldb/blob/master/db/db_impl.cc
Status DBImpl::Put(const WriteOptions& o, const Slice& key, const Slice& val) {
return DB::Put(o, key, val);
}
Status DB::Put(const WriteOptions& opt, const Slice& key, const Slice& value) {
WriteBatch batch;
batch.Put(key, value);
return Write(opt, &batch);
}
|
从上面的代码可以看出, Put 其实也是将单条数据的操作变更为一个批量操作,然后调用 Write 进行实现。
Delete 不会直接删除数据,而是在对应位置插入一个 key 的删除标志,然后在后续的 Compaction 过程中才最终去除这条 key-value 记录。其代码如下:
1
2
3
4
5
6
7
8
9
10
11
|
// https://github.com/google/leveldb/blob/master/db/db_impl.cc
Status DBImpl::Delete(const WriteOptions& options, const Slice& key) {
return DB::Delete(options, key);
}
Status DB::Delete(const WriteOptions& opt, const Slice& key) {
WriteBatch batch;
batch.Delete(key);
return Write(opt, &batch);
}
|
从上面的代码可以看出 Delete 的本质其实也是一个 Write 操作。
在介绍 Write 之前,首先介绍其封装的消息结构 Writer 与任务队列 writes_。
Writer 用于保存基本信息,如批量操作 batch、状态信息 status、是否同步 sync、是否完成 done 以及用于多线程操作的条件变量cv 。
1
2
3
4
5
6
7
8
9
10
11
12
|
// https://github.com/google/leveldb/blob/master/db/db_impl.cc
struct DBImpl::Writer {
explicit Writer(port::Mutex* mu)
: batch(nullptr), sync(false), done(false), cv(mu) {}
Status status; //状态
WriteBatch* batch; //批量写入对象
bool sync;//表示是否已经同步了
bool done;//表示是否已经处理完成
port::CondVar cv;//这个是条件变量
};
|
接着看看任务队列 writers_,该队列对象中的元素节点为 Writer 对象指针。可见 writes_ 与写操作的缓存空间有关,批量操作请求均存储在这个队列中,按顺序执行,已完成的出队,而未执行的则在这个队列中处于等待状态。
1
2
|
// https://weread.qq.com/web/reader/9f932e70727ac58e9f9d8cck636320102206364d3f0ffdc
std::deque<Writer*> writers_ GUARDED_BY(mutex_);
|

Write 主要有两个参数:WriteOptions 对象与 WriteBatch 对象。WriteOptions 主要包含一些关于写操作的参数选项,而WriteBatch对象,相当于一个缓冲区,用于定义、保存一系列的批量操作。其代码实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
|
// https://github.com/google/leveldb/blob/master/db/db_impl.cc
Status DBImpl::Write(const WriteOptions& options, WriteBatch* updates) {
//实例化一个Writer对象b并插入writers_队列中等待执行
Writer w(&mutex_);
w.batch = updates;
w.sync = options.sync;
w.done = false;
MutexLock l(&mutex_);
writers_.push_back(&w);
while (!w.done && &w != writers_.front()) {
w.cv.Wait();
}
if (w.done) {
return w.status;
}
Status status = MakeRoomForWrite(updates == nullptr);
uint64_t last_sequence = versions_->LastSequence();
Writer* last_writer = &w;
if (status.ok() && updates != nullptr) {
//合并写入操作
WriteBatch* write_batch = BuildBatchGroup(&last_writer);
WriteBatchInternal::SetSequence(write_batch, last_sequence + 1);
last_sequence += WriteBatchInternal::Count(write_batch);
{
mutex_.Unlock();
//将更新写入日志文件中,并且将日志文件写入磁盘中
status = log_->AddRecord(WriteBatchInternal::Contents(write_batch));
bool sync_error = false;
if (status.ok() && options.sync) {
status = logfile_->Sync();
if (!status.ok()) {
sync_error = true;
}
}
//将更新写入Memtable中
if (status.ok()) {
status = WriteBatchInternal::InsertInto(write_batch, mem_);
}
mutex_.Lock();
if (sync_error) {
RecordBackgroundError(status);
}
}
if (write_batch == tmp_batch_) tmp_batch_->Clear();
versions_->SetLastSequence(last_sequence);
}
//由于和并写入操作一次可能会处理多个writer_队列中的元素,因此将所有已经处理的元素状态进行变更,并且发送signal信号
while (true) {
Writer* ready = writers_.front();
writers_.pop_front();
if (ready != &w) {
ready->status = status;
ready->done = true;
ready->cv.Signal();
}
if (ready == last_writer) break;
}
//通知writers_队列中的第一个元素,发送signal信号
if (!writers_.empty()) {
writers_.front()->cv.Signal();
}
return status;
}
|
具体的实现流程如下图所示:
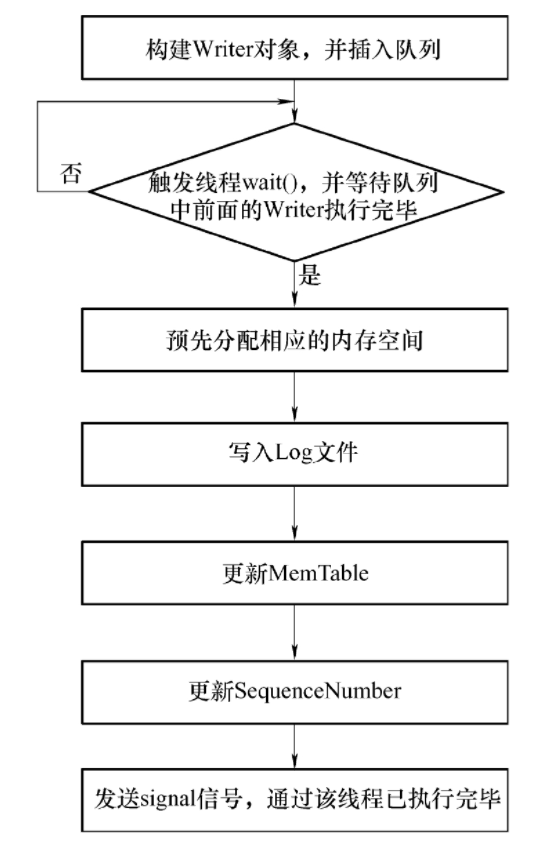
-
实例化一个 Writer 对象,并将其插入所示的 writers_ 队列中。
-
通过 Writer 中的条件变量 cv 调用 wait 方法将该线程挂起,等待其他线程发送 signal 信号,并且等待队列前面的 Writer 操作全部执行完毕:
- 如果线程收到了 signal 信号:则解除阻塞。
- 如果线程没有收到了 signal 信号:说明队列前面仍有其他的 Writer 操作,那么该线程会再次调用
wait 方法实现阻塞,从而保证了 Writer 操作按照队列生成次序执行。
-
当轮到本线程操作时,首先通过 MakeRoomForWrite 函数进行内存空间分配。
-
当获取到需要的内存后,根据一系列的批量操作,对 Log 文件以及 MemTable 分别进行更新。
-
依据批量操作的数目更新 SequenceNumber。
-
通过 Writer 中的条件变量 cv 发送 signal 信号,以通知处于等待状态的其他线程开始执行。