数据类型
基础数据类型
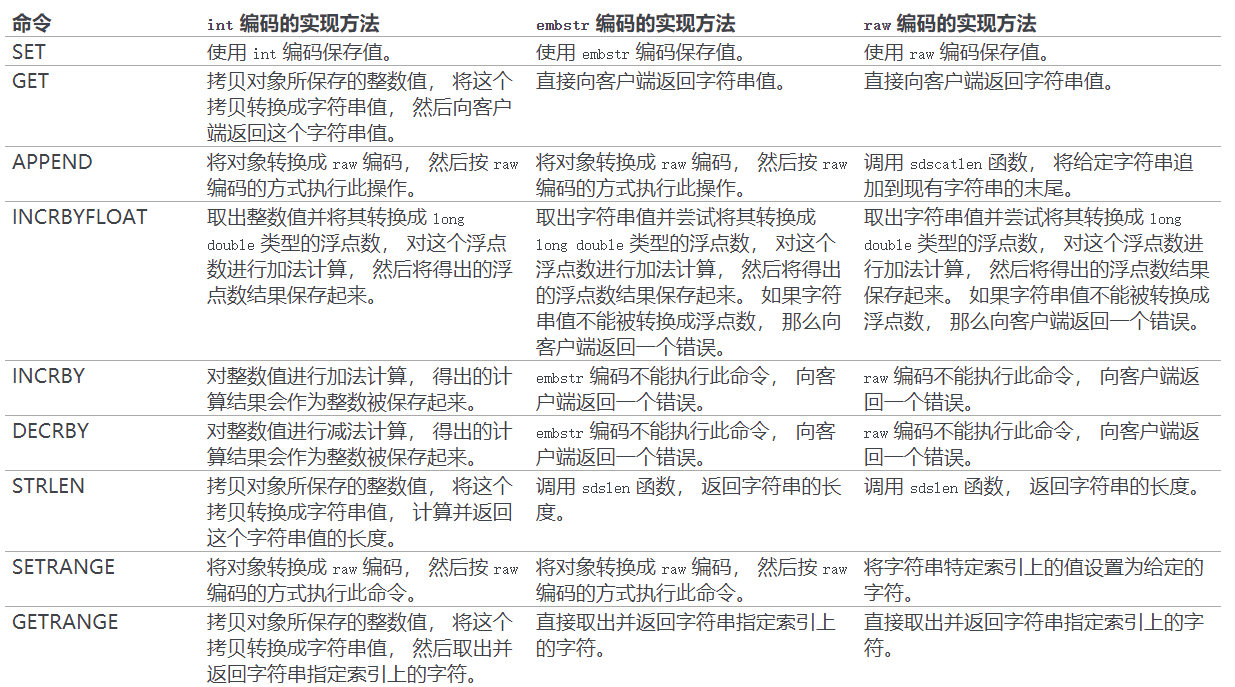
String
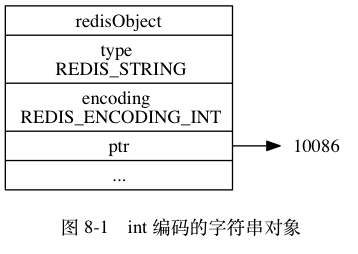
字符串类型(SDS)即简单动态字符串,它是以键值对key-value的形式进行存储的,根据 key 来存储和获取value值
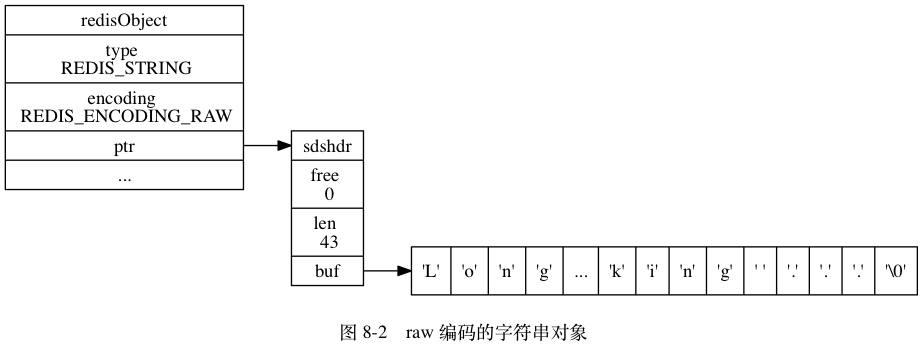
依据不同情况,字符串在底层会使用 int 、 raw 或者 embstr 三种不同的编码格式
- 如果数据为可以使用long类型来保存的整数,则使用int
- 如果数据为可以使用long double类型来保存的浮点数,则使用embstr或者raw
- 如果数据为字符串,或者长度过大没办法用long来表示的整数,以及长度过大无法用long double表示的浮点数,则使用embstr或者raw。当数据小于39字节时,使用embstr,当大于39字节时使用raw

基本用法
|
|
使用场景
- 存放用户(登录)信息;
- 存放文章详情和列表信息;
- 存放和累计网页的统计信息。
Hash
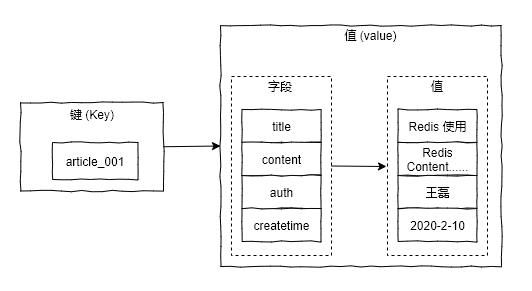
字典类型 (Hash) 又被成为散列类型或者是哈希表类型,它是将⼀个键值 (key) 和⼀个特殊的“哈希表”关联起来。
哈希类型的底层数据结构可以是压缩列表(ZipList)或者字典(Dict)
- 当哈希对象的所有键值对的键和值的字符串长度都小于64字节,并且保存的键值对数量小于512个时,使用压缩列表
- 如果不满足上述条件中的任意一个,都会使用字典
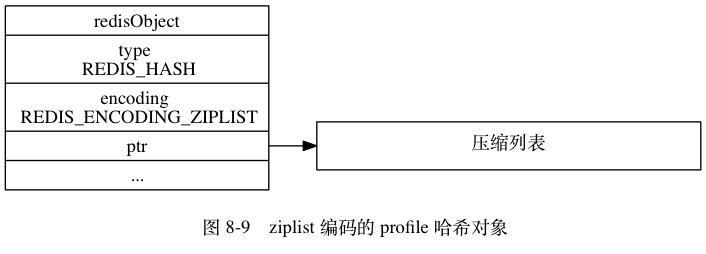
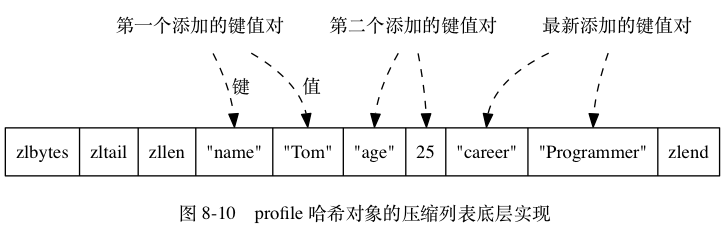
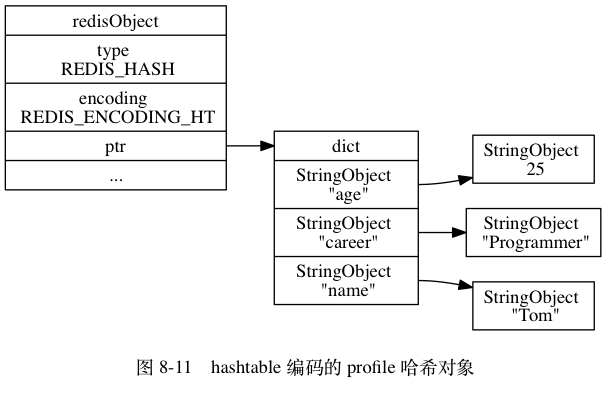
基本用法
|
|

使用场景
- 存储用户信息或者某个物品的信息,无需序列化,直接建立映射
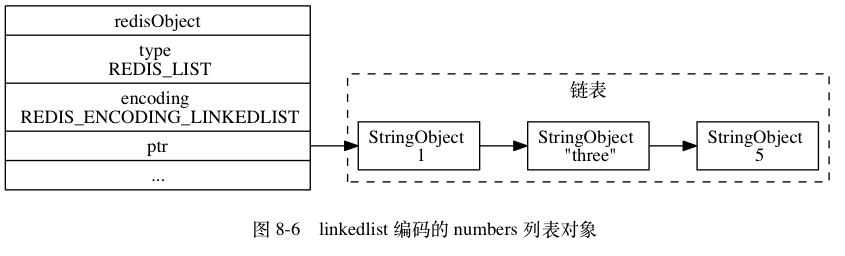
List
列表类型 (List) 是⼀个使用线性结构存储的结构,它的元素插入会按照先后顺序存储到链表结构中。 列表类型的底层数据结构可以是压缩列表(ZipList)或者链表(LinkedList)
- 当列表对象的所有字符串元素长度都小于64字节,并且保存的元素数量小于512个时,使用压缩列表
- 如果不满足上述条件中的任意一个,都会使用链表
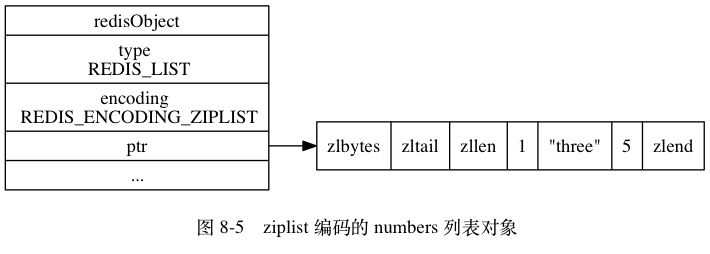
基本用法
|
|
使用场景
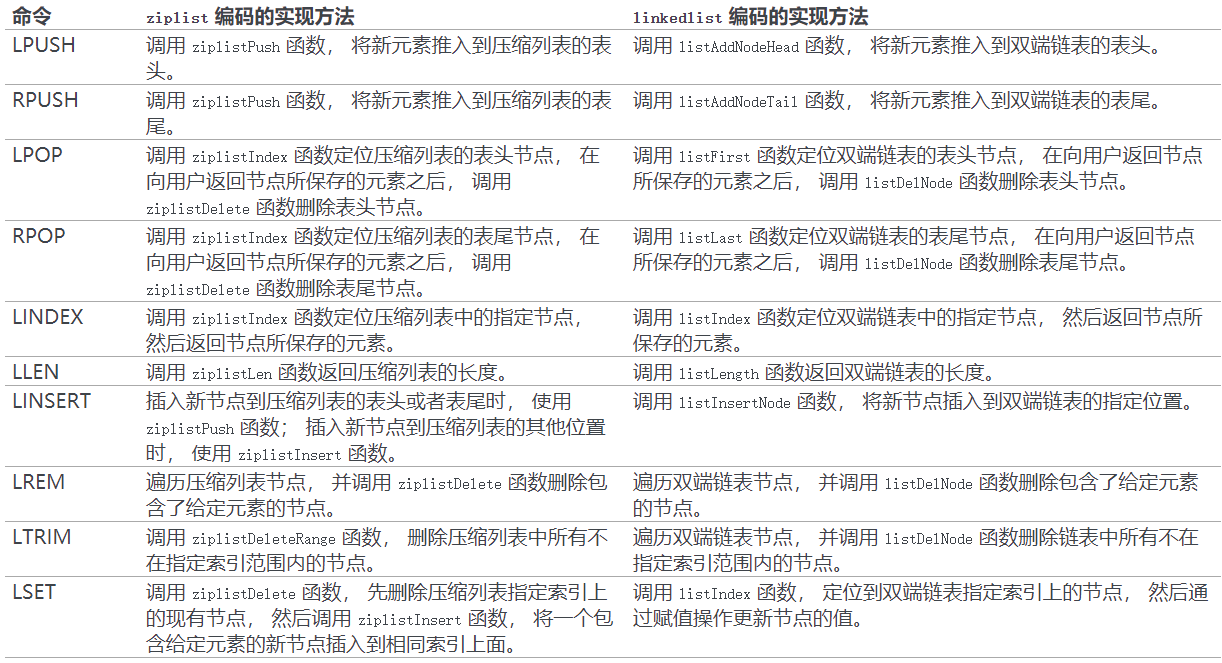
- 消息队列:列表类型可以使用 rpush 实现先进先出的功能,同时又可以使用 lpop 轻松的弹出(查询并删除)第⼀个元素,所以列表类型可以用来实现消息队列;
- 文章列表:对于博客站点来说,当用户和文章都越来越多时,为了加快程序的响应速度,我们可以把用户自己的文章存入到 List 中,因为 List 是有序的结构,所以这样不仅可以完美的实现分页功能,而且加速了程序的响应速度。
Set
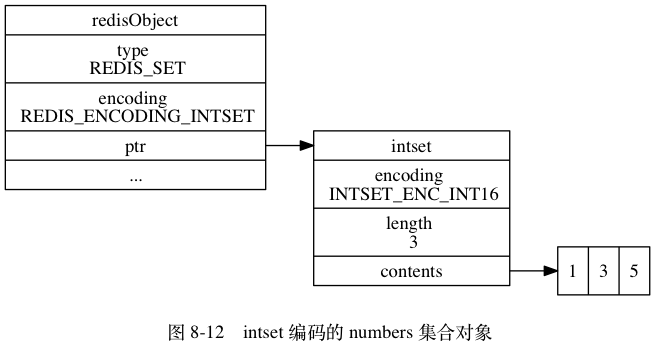
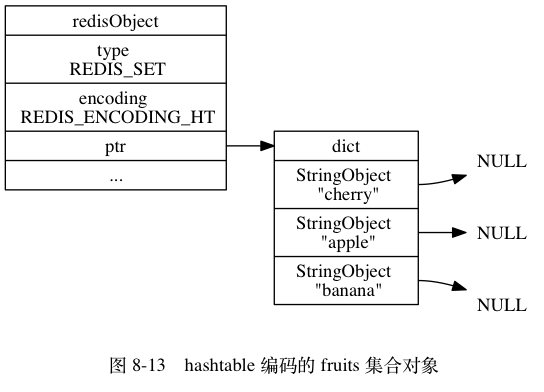
集合类型 (Set) 是⼀个无序并唯⼀的键值集合。
集合类型的底层数据结构可以是整数集合(IntSet)或者字典(Dict)
- 当集合对象的所有元素都是整数值,并且保存的元素数量小于512个时,使用整数集合
- 如果不满足上述条件中的任意一个,都会使用字典
基本用法
|
|

使用场景
- 微博关注我的人和我关注的人都适合用集合存储,可以保证人员不会重复;
- 中奖人信息也适合用集合类型存储,这样可以保证⼀个人不会重复中奖。
Zset
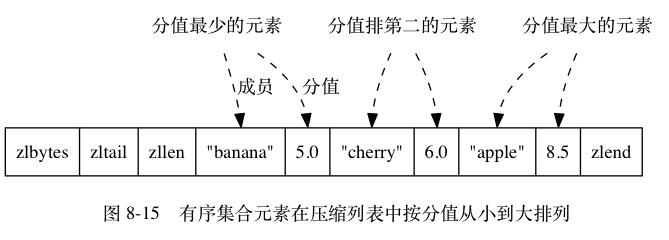
有序集合类型 (SortedSet) 相比于集合类型多了⼀个排序属性 score(分值),所以对于有序集合ZSet 来说,每个存储元素相当于有两个值组成的,⼀个是有序结合的元素值,⼀个是分值。有序集合的存储元素值也是不能重复的,但分值是可以重复的。
有序集合类型的底层数据结构可以是压缩列表(ZipList)或者跳表(SkipList )
- 当有序集合对象的所有元素成员的长度都小于64字节,并且保存的元素数量小于128个时,使用压缩列表
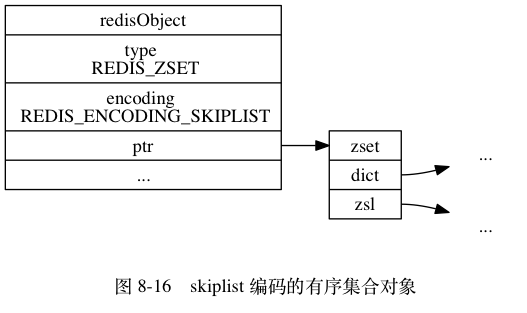
- 如果不满足上述条件中的任意一个,都会使用跳表(这里的跳表是结合字典的)
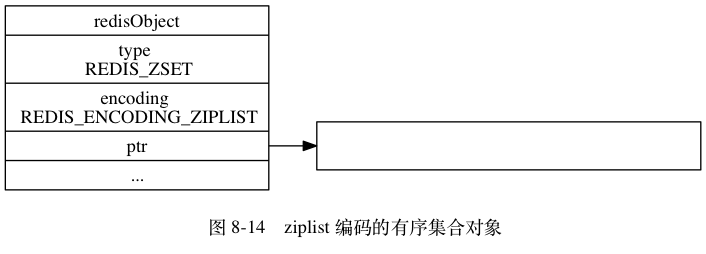
 这里不是直接使用跳表,而是搭配字典一起使用
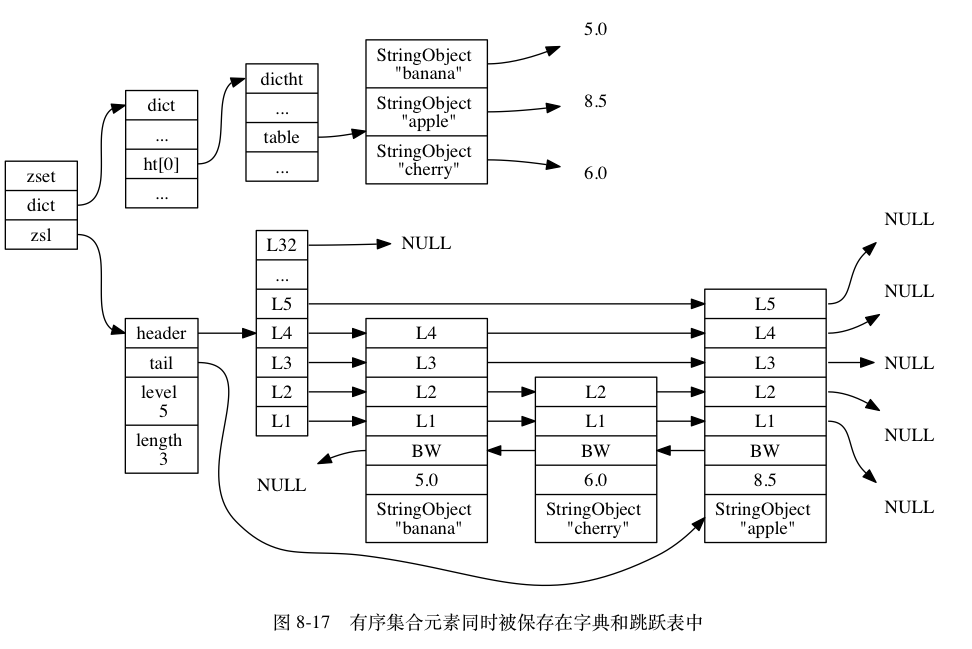
之所以这样设置是因为考虑到如果直接使用跳跃表,如果需要查找成员的分值时只能通过遍历来进行查找,而这样的效率是O(logN)
而字典虽然建立映射后可以O(1)的查找到分值,但是哈希只能通过key值进行查找,并不支持范围查询。
所以将两者进行结合,使用字典建立起元素与分值的映射,使用字典来进行成员分数的查找,而使用跳跃表来进行范围型操作,这样就很好的解决了这个问题。
这里不是直接使用跳表,而是搭配字典一起使用
之所以这样设置是因为考虑到如果直接使用跳跃表,如果需要查找成员的分值时只能通过遍历来进行查找,而这样的效率是O(logN)
而字典虽然建立映射后可以O(1)的查找到分值,但是哈希只能通过key值进行查找,并不支持范围查询。
所以将两者进行结合,使用字典建立起元素与分值的映射,使用字典来进行成员分数的查找,而使用跳跃表来进行范围型操作,这样就很好的解决了这个问题。
|
|
基本用法
|
|

使用场景
- 学生成绩排名;
- 粉丝列表,根据关注的先后时间排序。
特殊数据类型
Geospatial(地理空间)
在使用一些小程序的时候,里面通常都会通过定位使用者的位置,来显示附近的人、外卖距离、剩余路径等功能,在Redis3.2中也引入了推算地理信息的数据结构,即Geospatial
介绍
把某个具体的位置信息(经度,纬度,名称)添加到指定的key中,数据将会用一个sorted set存储,以便稍后能使用 GEORADIUS和 GEORADIUSBYMEMBER命令来根据半径来查询位置信息。
这个命令(指GEOADD)的参数使用标准的x,y形式,所以经度(longitude)必须放在纬度(latitude)之前,对于可被索引的坐标位置是有一定限制条件的:非常靠近极点的位置是不能被索引的, 在EPSG:900913 / EPSG:3785 / OSGEO:41001指定如下:
- 有效的经度是-180度到180度
- 有效的纬度是-85.05112878度到85.05112878度
上面是官方文档的描述,其实Geo并没有我们想象中的复杂,它的本质就是一个Zset,通过将坐标以Geohash的方式进行处理,将经度纬度错位后形成一个52位整数,所以我们同样能够使用Zset提供的接口来操作Geo。
用法
| 命令 | 作用 |
|---|---|
| GEOADD key 经度 纬度 地点名称 | 将指定的地理空间位置(经度、纬度、名称)添加到指定的key中 |
| GEODIST key 地点1 地点2 | 返回两个给定位置之间的距离 |
| GEOPOS key 地点 | 从key里返回所有给定位置元素的位置(经度和纬度) |
| GEOHASH key 地点 | 返回一个或多个位置元素的 Geohash 表示 |
| GEORADIUS key 经度 纬度 半径 | 以给定的经纬度为中心, 找出某一半径内的元素 |
| GEORADIUSBYMEMBER key 地点 半径 | 找出位于指定范围内的元素,中心点是由给定的位置元素决定 |
| Zset的接口同样适用于Geo,因此需要删除、查询全部时就可以使用Zset的接口。 |
下面示范一下这些命令的使用方式
|
|
Hyperloglog(基数统计)
在我们为网站统计访问量、日活量时,由于我们统计的是用户数量而非访问次数,因此即使一个用户多次访问也只会统计一次,这种不重复的数据通常被称为基数。
在传统的做法中,我们通常会采用set来保存用户的ID来进行计数,因为其本身存在着去重的功能,但是由于我们所需要的是对用户进行计数,如果通过将所有用户的ID保存的方法来完成,当用户量大的时候就会对内存产生巨大的压力,并且效率也大大降低。
为了解决这个问题,Redis在2.8.9版本添加了HyperLogLog结构。
介绍
Redis HyperLogLog是用来做基数统计的算法,HyperLogLog的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且是很小的。
在Redis 里面,每个HyperLogLog键只需要花费12KB内存,就可以计算接近2^64个不同元素的基数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,由于HyperLogLog使用的是概率算法,通过存储元素的hash值的第一个1的位置,来计算元素数量,所以HyperLogLog 不会存储元素本身,在数据量大的时候也可能会存在一定的误差。但是在基数统计这一方面,它的效果是其他结构无法比拟的。
用法
| 命令 | 作用 |
|---|---|
| PFADD key value | 添加指定的值到Hyperloglog中 |
| PFCONUT key | 返回给定Hyperloglog的基数估算值 |
| PFMERGE destkey sourcekey | 将目标Hyperloglog合并到源Hyperloglog中 |
使用示范
|
|
Bitmap(位图)
介绍
位图其实就是哈希的变形,他通过哈希映射来处理数据,位图本身并不存储数据,而是存储标记。通过一个比特位,即0/1来标记一个数据的两种状态
位图通常情况下用在数据量庞大,且数据不重复的情景下标记某个数据的两种状态。 我们可以使用位图来记录当前用户的登陆情况、或者实现打卡、签到等功能。
用法
| 命令 | 作用 |
|---|---|
| GETBIT key offset value(0/1) | 设置Bitmap中偏移量为offset的位置的值 |
| SETBIT key offset value | 返回Bitmap中偏移量为offset的位置的值 |
| BITCOUNT key | 计算位图中有多少个1 |
|
|